简介
说明
本文打断点来分析Spring(SpringBoot)是如何解决循环依赖的。
相关网址
调用到此处代码的流程见:SpringBoot原理–启动流程 – 自学精灵
Bean初始化流程:Spring–Bean的创建过程/获取流程 – 自学精灵
定位代码位置
由上边两篇博客,可以定位到实例化的代码位置:
AbstractAutowireCapableBeanFactory#doCreateBean(beanName, mbdToUse, args)
系列文章
- Spring循环依赖的原理系列(一)–什么是循环依赖 – 自学精灵
- Spring循环依赖的原理系列(二)–打断点分析 – 自学精灵
- Spring循环依赖的原理系列(三)–原理概述 – 自学精灵
- Spring循环依赖的原理系列(四)–为什么用三级缓存,而不是二级 – 自学精灵
1.总入口:populateBean
总结
经过下边的定位,可确定,核心代码在:AbstractAutowireCapableBeanFactory#populateBean(beanName, mbd, instanceWrapper);
doGetBean 中有两个 getSingleton 方法会先后执行。第一个是尝试从缓存中获取,若缓存中没有 A,则执行第二个,通过工厂获得。
public Object getSingleton(String beanName) 。
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory)。
第一次通过getSingleton(String beanName)获取bean的时候,缓存中是没有的,于是走到getSingleton(String beanName, ObjectFactory<?> singletonFactory)
流程概述
getBean(beanName) //AbstractBeanFactory抽象类(实现的BeanFactory接口)
doGetBean(name, null, null, false) //AbstractBeanFactory抽象类。自己的方法。
// 先从单例的缓存中取,取不到则走下一个getSingleton
getSingleton(beanName);
getSingleton(beanName, () -> {
try {
return createBean(beanName, mbd, args);
}}
)
createBean(beanName, mbd, args) //AbstractAutowireCapableBeanFactory抽象类(实现的AbstractBeanFactory)
doCreateBean(beanName, mbdToUse, args)//AbstractAutowireCapableBeanFactory抽象类。以下为此类方法
createBeanInstance(beanName, mbd, args); //创建实例
applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName) //post-processors修改bean的定义
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean)); //解决循环依赖
populateBean(beanName, mbd, instanceWrapper); //填充属性
断点调试
打条件断点(DefaultListableBeanFactory#doCreateBean(beanName, mbdToUse, args)
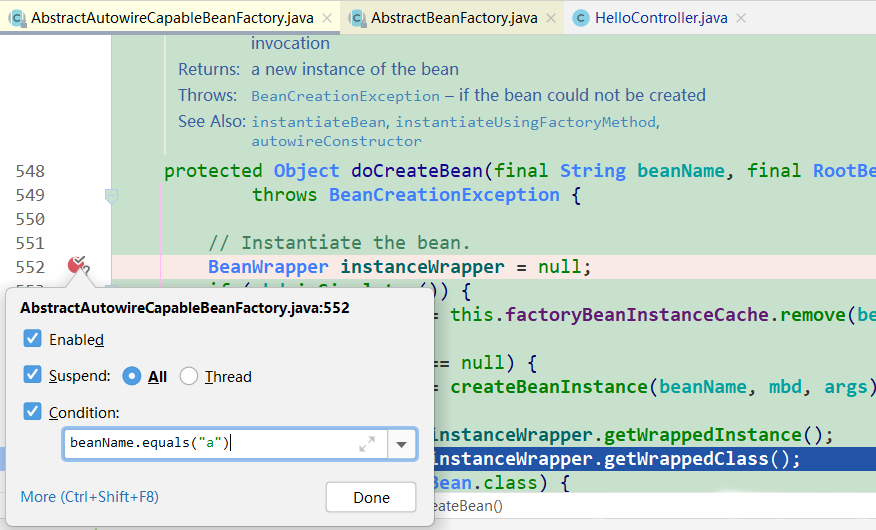
定位代码
实例化A时去实例化B并填充到A对象
在populateBean前后打断点。
结果:
- populateBean前(A的):A已经实例化,其字段b还是null。(图1)
- populateBean后(A的):没走到下一行,而是去实例化B去了,再次到了populateBean前。(图2)
- 此时,B已经实例化,其字段a为null
- populateBean后(B的):的对象里已经给字段a赋值了,但a的字段b仍然为null。(图3)
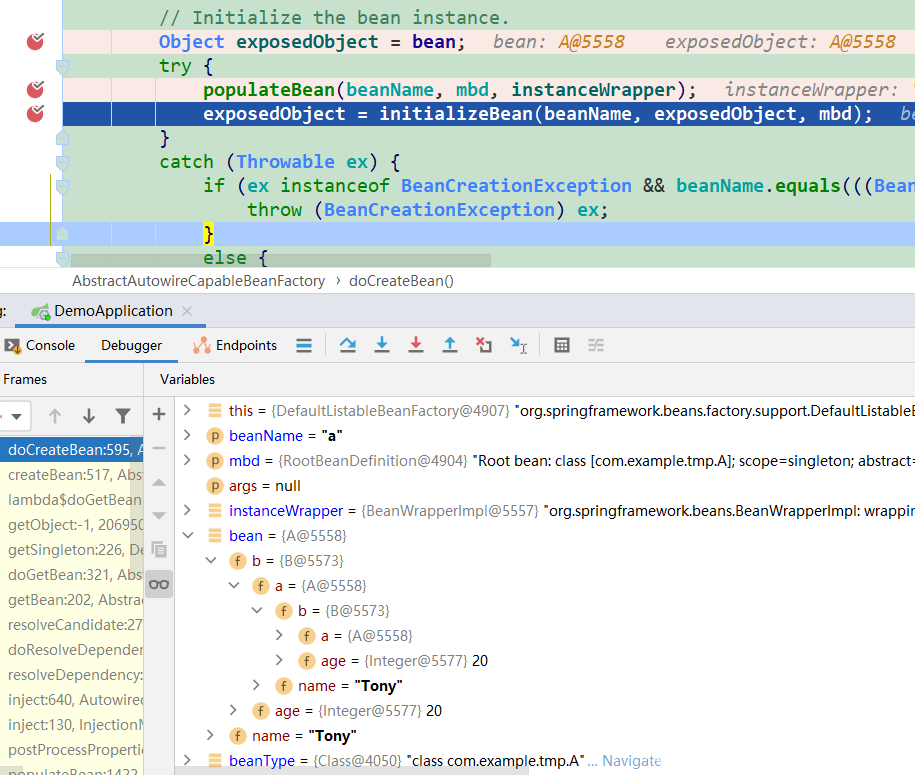
- populateBean后(A的):在第3步执行完之后,堆栈执行到A的populateBean后边。(图4)
- 此时,A对象里有B对象,B对象里边有A对象,一直循环
图1:
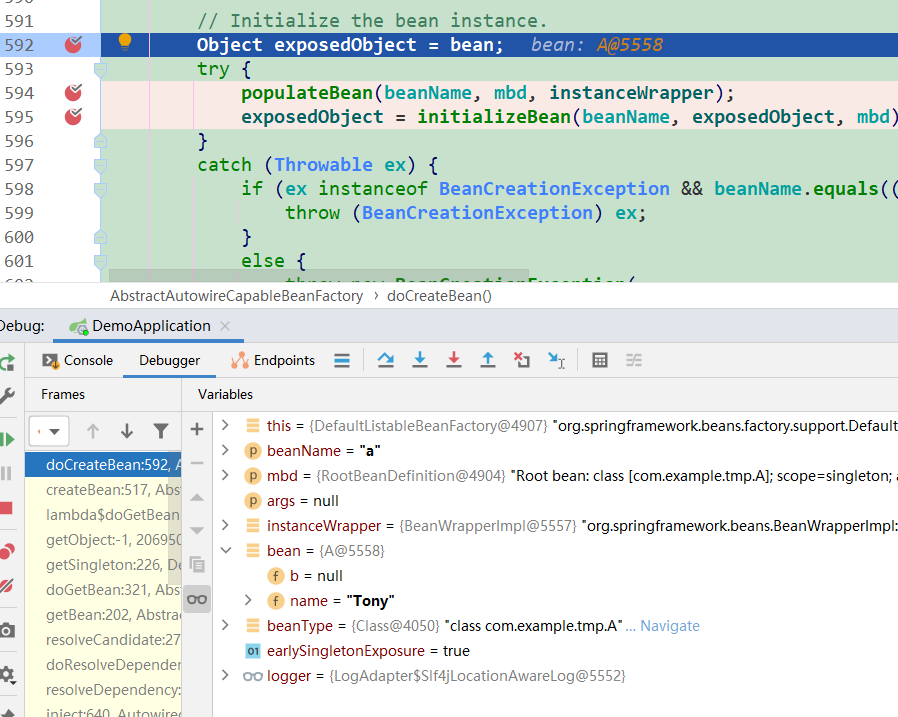
图2:

图3:
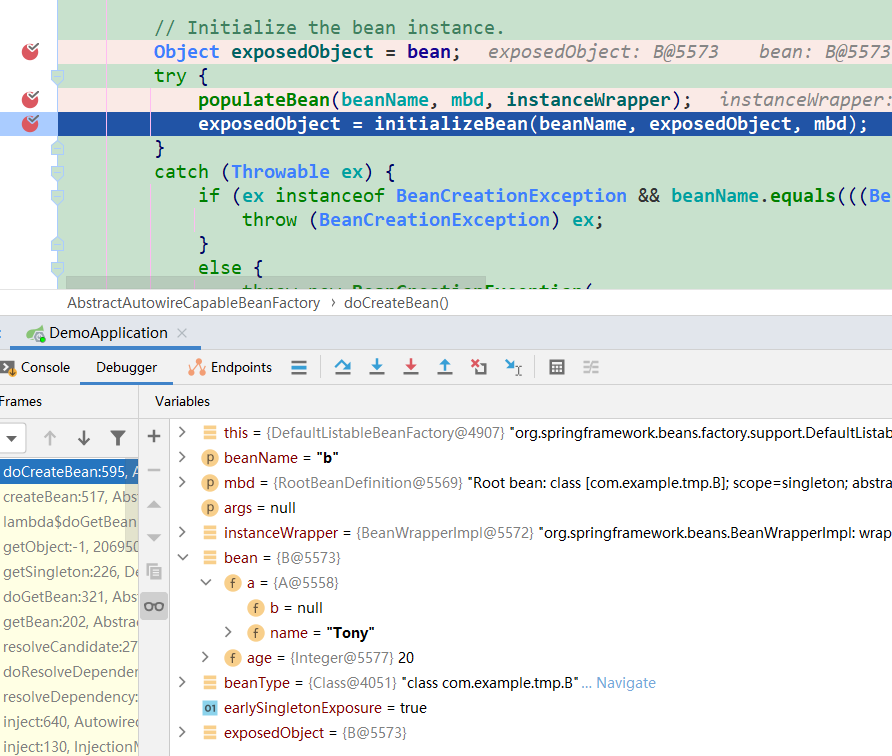
图4:
2.后置处理器注入属性
简介
经过上边的定位,可以确定,核心代码在:AbstractAutowireCapableBeanFactory#populateBean(beanName, mbd, instanceWrapper);
打条件断点:
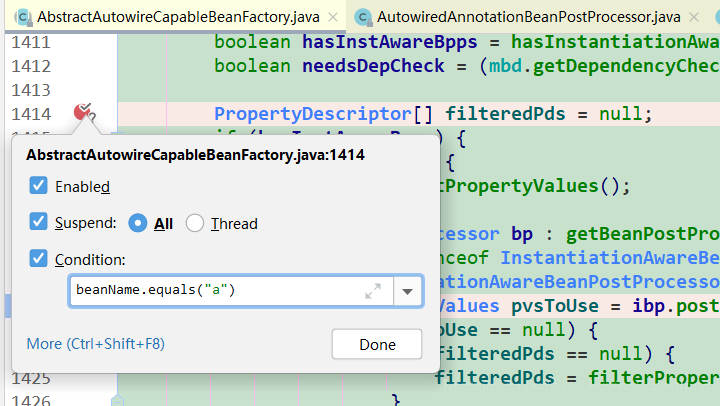
总结(代码流程)
getBeanPostProcessors() // 其中有:AutowiredAnnotationBeanPostProcessor (图1)
ibp.postProcessProperties(pvs, bw.getWrappedInstance(), beanName);
// AutowiredAnnotationBeanPostProcessor
postProcessProperties(PropertyValues pvs, Object bean, String beanName) (图2)
InjectionMetadata metadata = findAutowiringMetadata(beanName, bean.getClass(), pvs);
metadata.inject(bean, beanName, pvs);
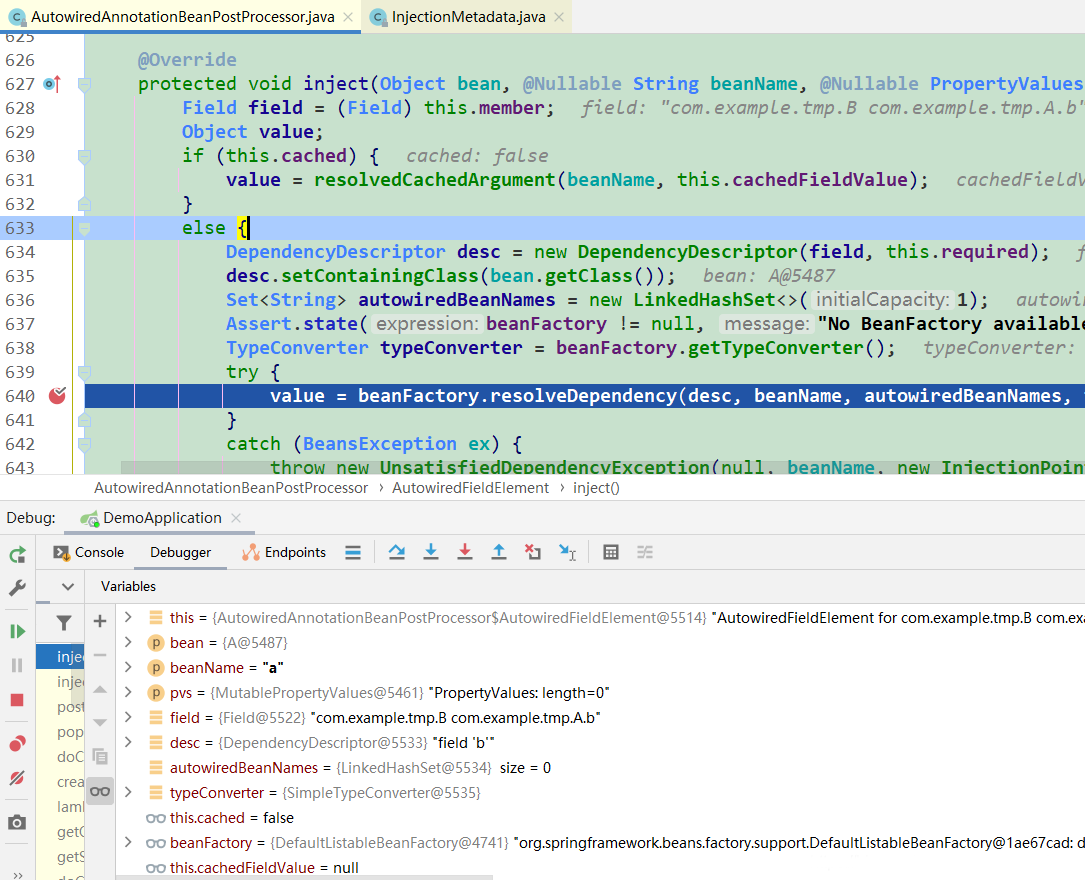
inject(bean, beanName, pvs) //InjectionMetadata
element.inject(target, beanName, pvs); //InjectionMetadata (图3)
// AutowiredAnnotationBeanPostProcessor
// 第一次进来时,this.cached为false。去解决依赖(B对象)(图4)
value = beanFactory.resolveDependency(desc, beanName, autowiredBeanNames, typeConverter)
// 上边获得之后,使用反射,设置字段的值
field.set(bean, value);
图1:
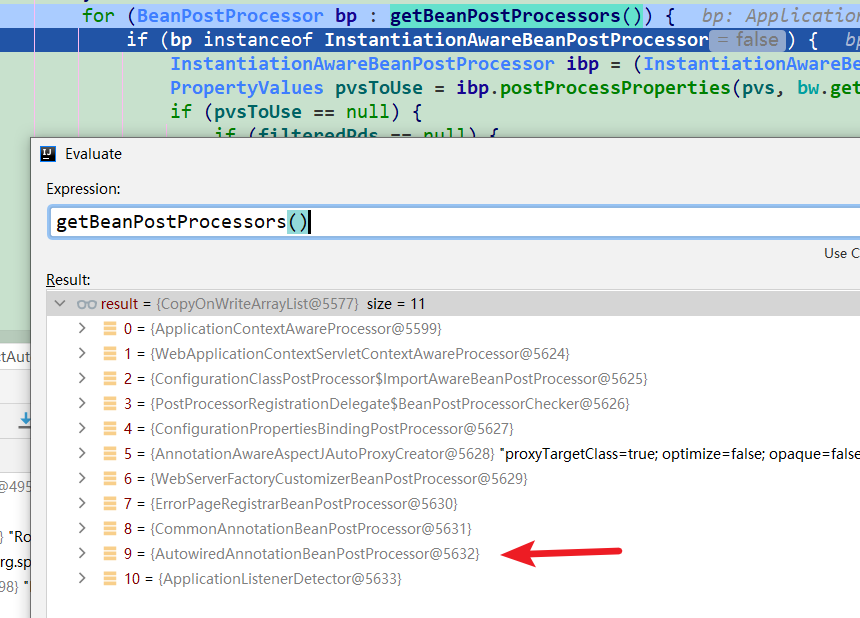
图2:
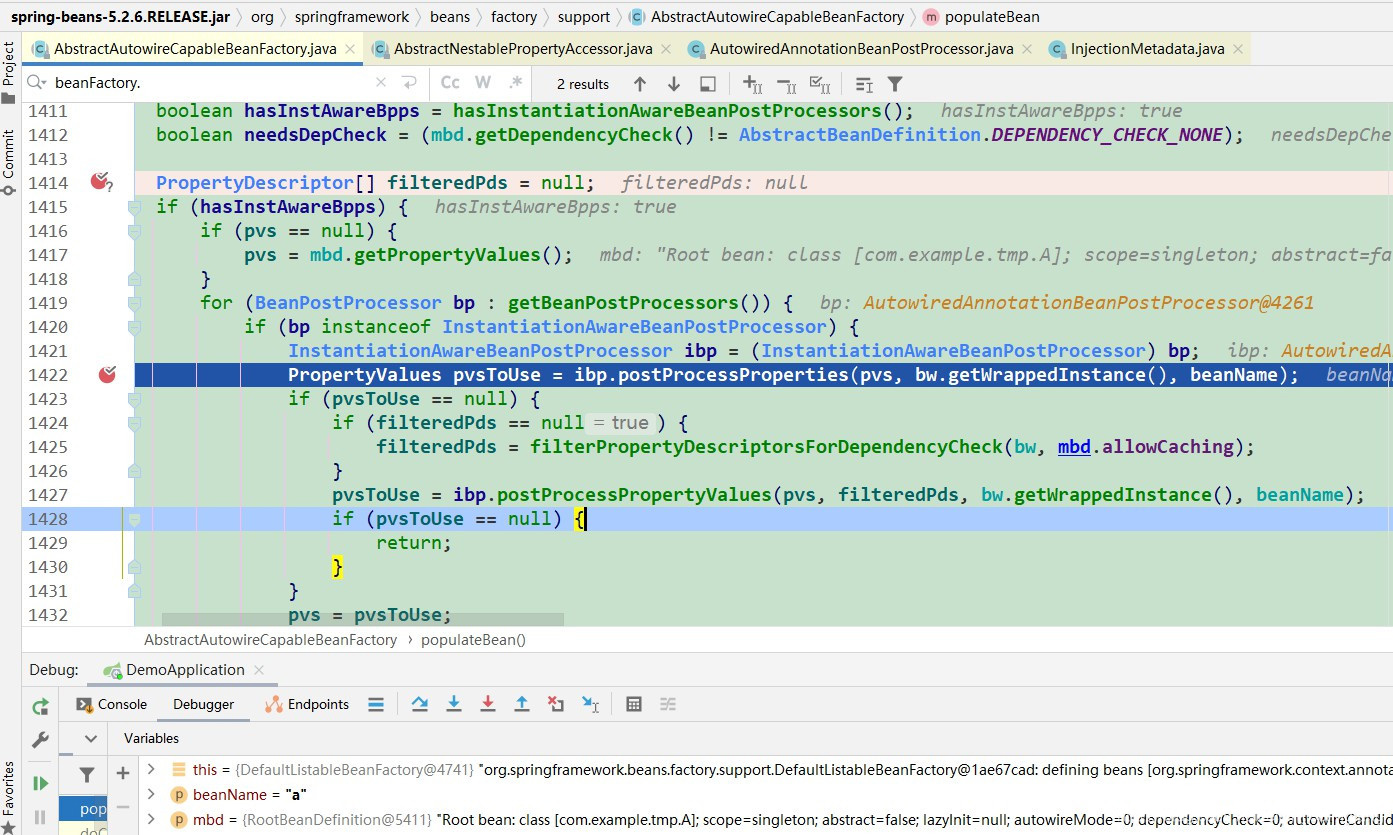
图3:
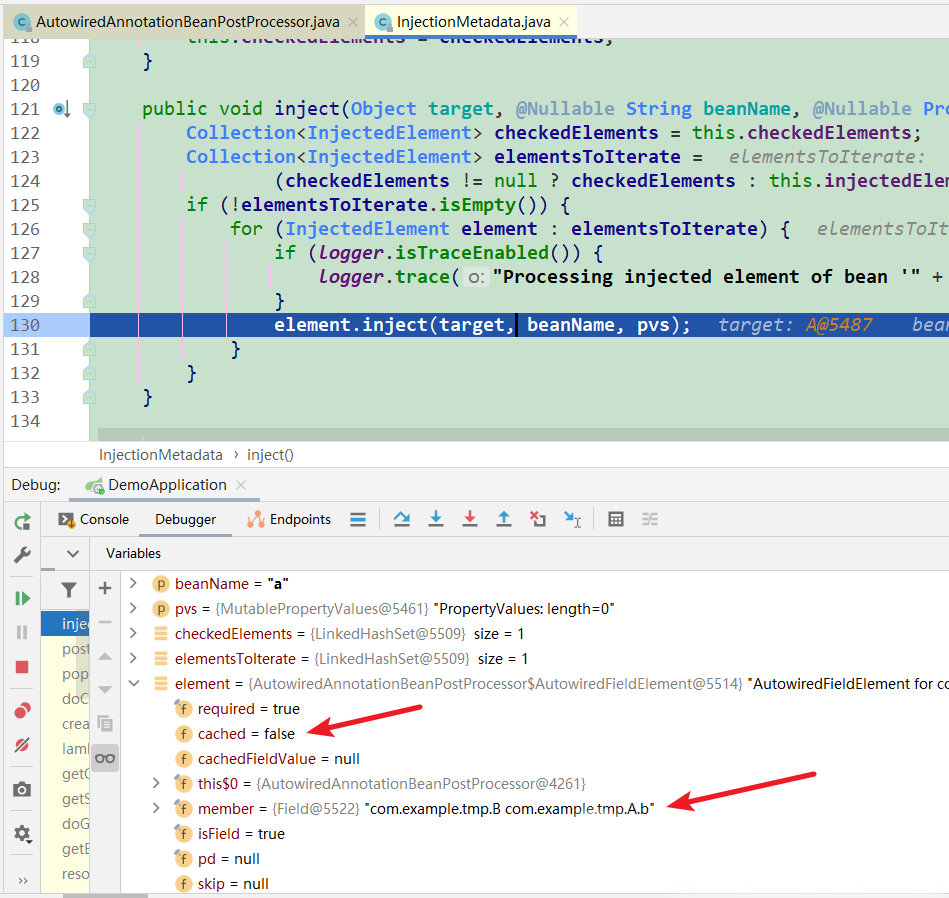
图4:
3.解决依赖
总结
实例化B时,由于之前实例化过A,这次 getSingleton(String beanName) 中发生了不一样的事:能够获得 A 的缓存。
简介
从上一步可以看到,最终调用DefaultListableBeanFactory#resolveDependency,来解决 A => B 的依赖,需要去获取 B,仍然通过 getBean 获取,和之前说 getBean 获取 A 的过程类似,只是这次换成了 B。
调用栈如下:getBean=> doGetBean=> getSingleton,又是熟悉的步骤,但这次 getSingleton(String beanName) 中发生了不一样的事:能够获得 A 的缓存。

4.三级缓存
总结
可以在第3级缓存中获得到bean。
简介
在AbstractBeanFactory#doGetBean()上打两个条件断点:beanName.equals(“a”) || beanName.equals(“b”)
// 为什么不在getSingleton里边打断点?因为getSingleton除了获取bean之外,其他也有地方调用了,会影响我们本处的分析。
断点1:

断点2:
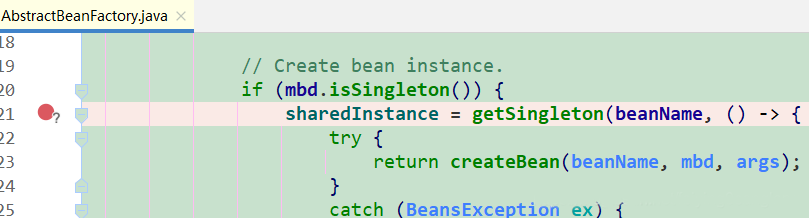
第1次到达断点1:Controller对象获取A对象,三级缓存中都没有
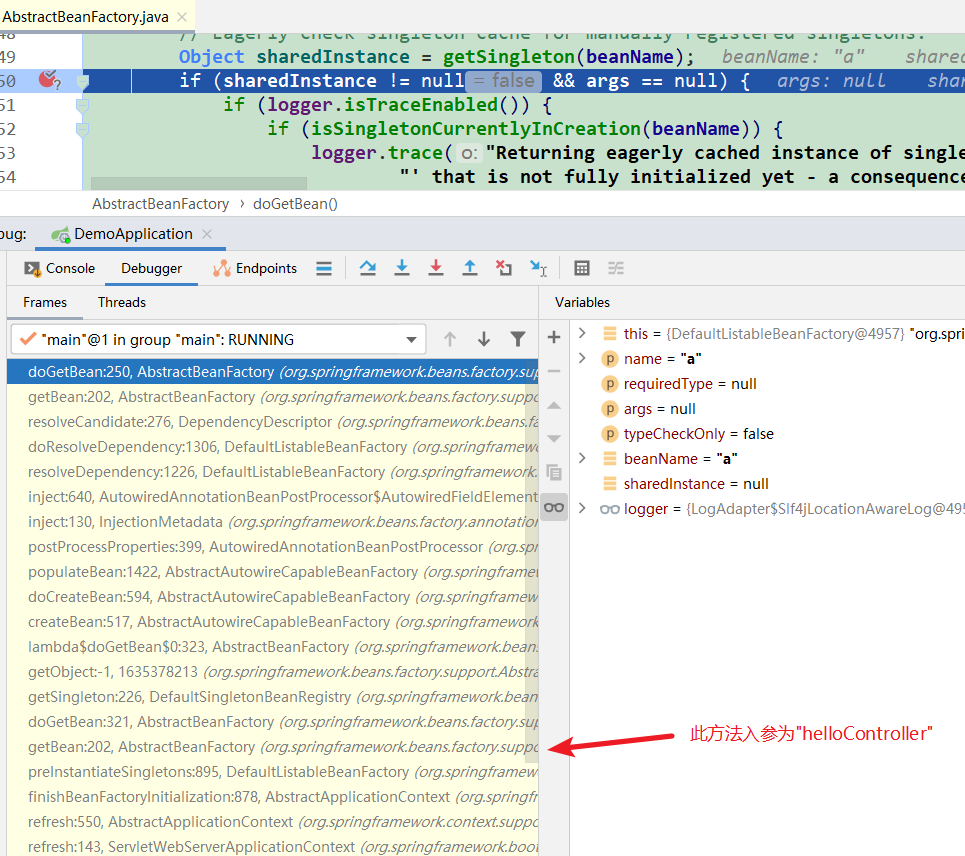
第1次到达断点2:缓存中都没有对象A,所以去创建
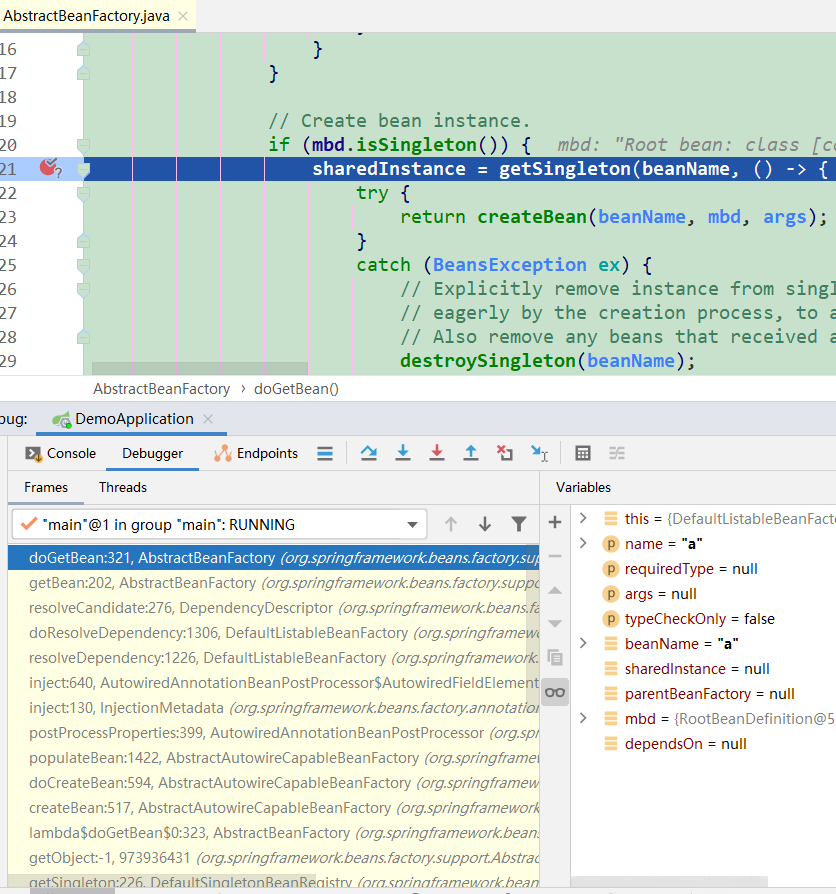
第2次到达断点1: 因为A类依赖了B类,所以获取B对象。但也是:三级缓存中都没有B对象
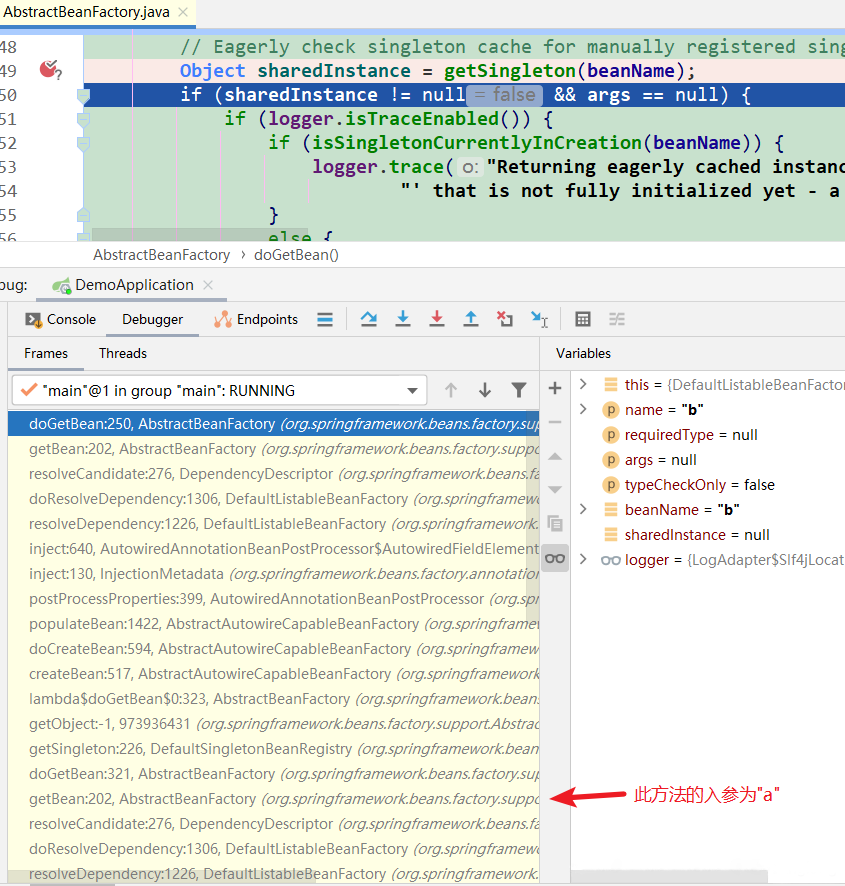
第2次到达断点2: 缓存中都没有对象B,所以去创建
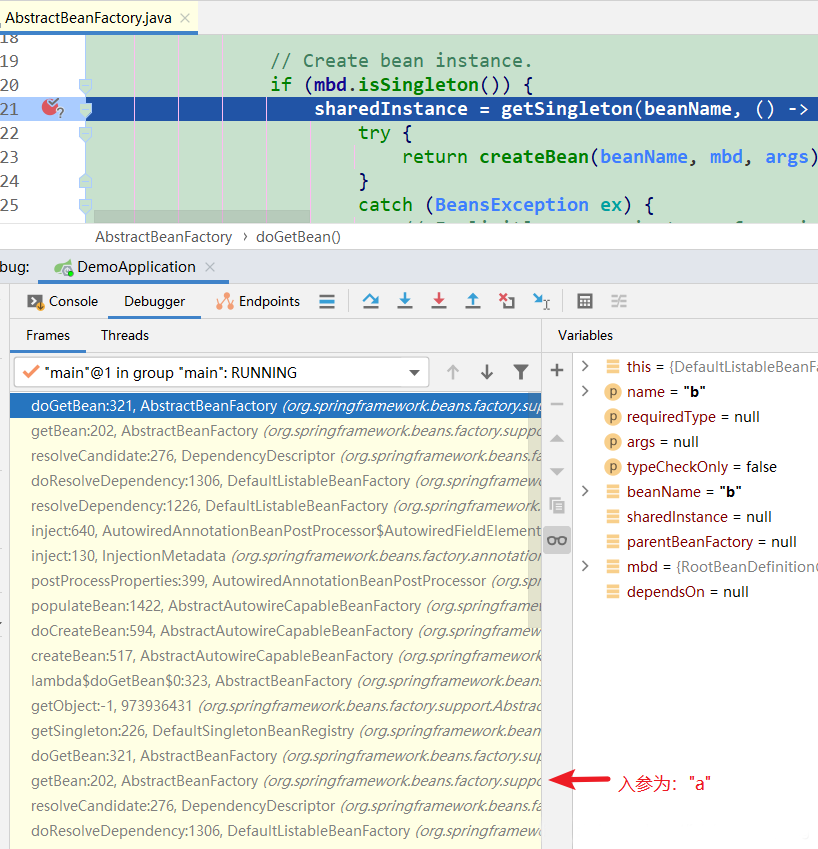
第3次到达断点1: 因为B类依赖了A类,所以获取A对象。此时:第1级缓存中已经有A对象了
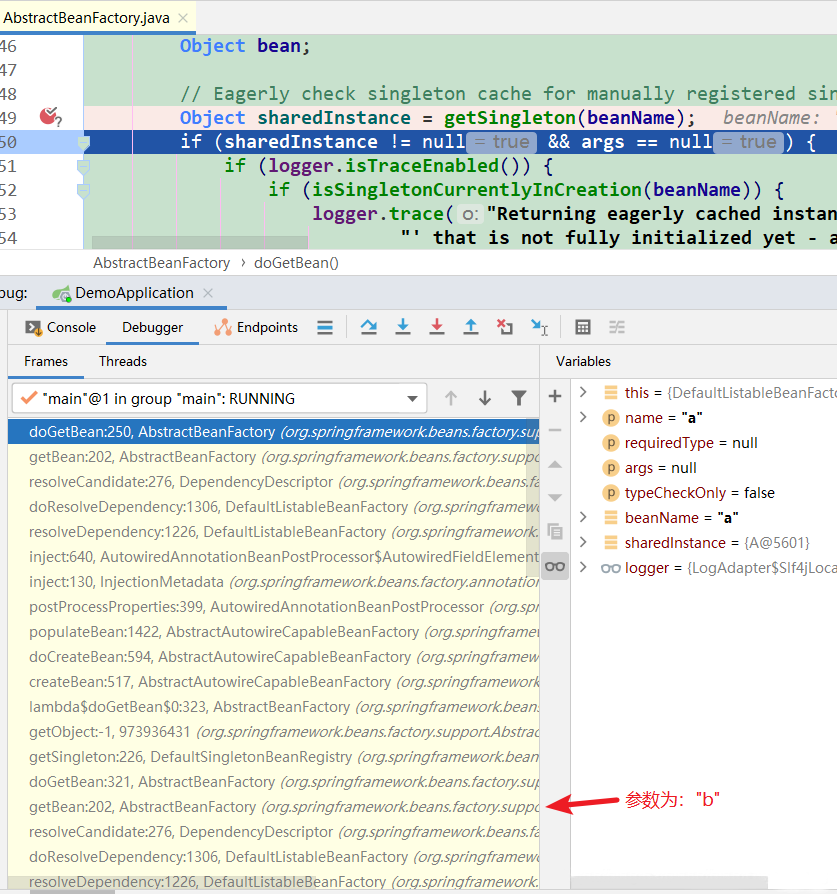
第4次到达断点1:A用@Component修饰,要扫描进来。此时缓存中已经有了
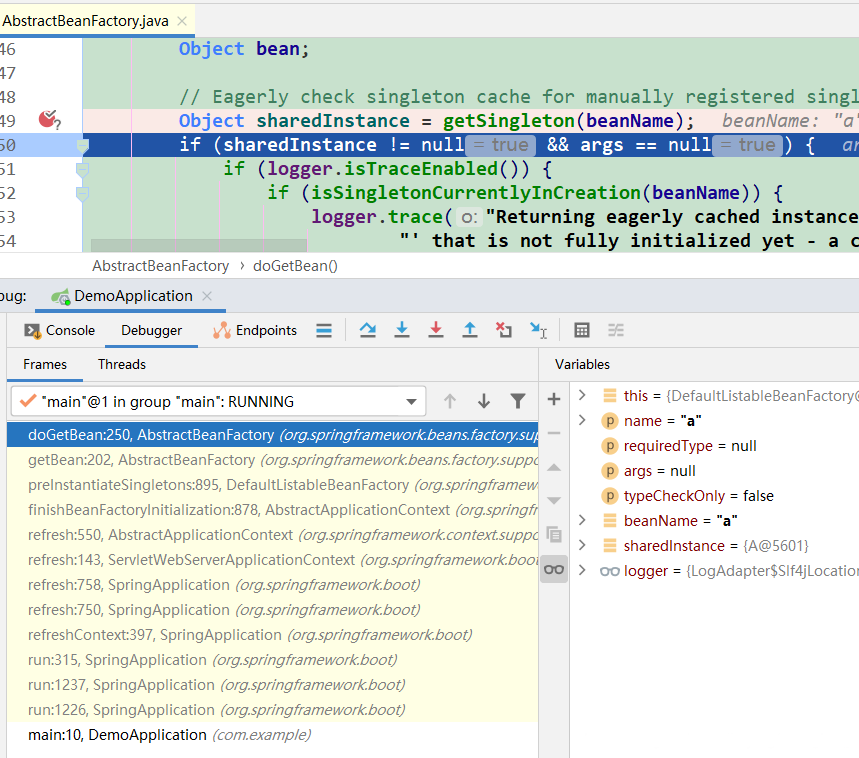
第5次到达断点1:B用@Component修饰,要扫描进来。此时缓存中已经有了

请先 !