简介
本文分享kafka主题、分区与消费者的关系。
kafka 为了保证消息顺序性(FIFO),一个partition只能被同一组的一个consumer消费。
不同组的consumer可以消费同一个partition,一个consumer可以消费多个partition。
相关网址
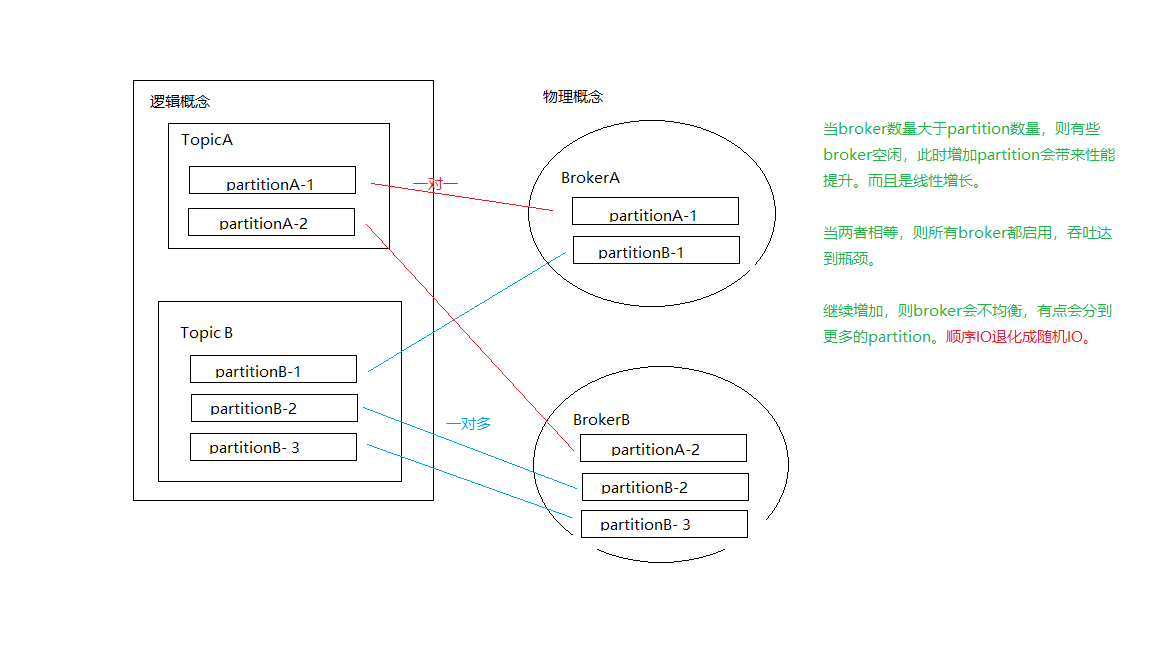
主题与分区
为什么要分区?
将topic的消息打散到多个分区,分布式地保存在不同的broker上,可以提高producer和consumer处理消息的吞吐量。
Kafka的producer和consumer都可以多线程地并行操作,而每个线程处理的是一个分区的数据。因此分区实际上是调优Kafka并行度的最小单元。
对于producer而言,它是用多个线程并发地向不同分区所在的broker发起Socket连接同时给这些分区发送消息;而consumer,同一个消费组内的所有consumer线程都被指定topic的某一个分区进行消费。
最佳实践
如果一个broker只有某topic的一个partition,能最大限度发挥顺序写的优势。
如果一个broker对应某topic的多个partition,需要随机分发,顺序IO会退化成随机IO,性能下降。
最佳分配是:broker的数量等于topic的partition数量。此时Kafka会自动将topic的partition平均分到每一个broker上(一个broker对应topic的一个partition)。如果broker多于partition,则broker没有得到充分利用;如果broker少于partition,会导致某个broker对应topic的多个partition,则会导致随机IO,性能下降。
测试:3个 Broker,1个 Topic,无Replication,异步,3个 Producer,消息 Payload 为100字节。
第一阶段
当 Partition 数量小于 Broker个数时,Partition 数量越大,吞吐率越高,且呈线性提升。
Kafka 会将所有 Partition 均匀分布到所有Broker 上,所以当只有2个 Partition 时,会有2个 Broker 为该 Topic 服务。
3个 Partition 时,同理会有3个 Broker 为该 Topic 服务。
第二阶段:
当 Partition 数量多于 Broker 个数时,总吞吐量并未有所提升,甚至还有所下降。
Topic瓶颈
Topic多时,性能明显降低。单机超过64个队列(分区),负载明显升高,且分区越多,发送消息响应时间越长。
原因是:在Broker上,每一个分区都是一个单独的文件。如果Topic变多,分区数也会上升,原本的顺序读写会变成随机读写,性能极度下降。
分区与消费者
消费者数量最好和分区数量一致。
1.消费者多于分区数
Topic: T1有1个partition
Group: G1组有2个consumer
消费者数量为2大于partition数量1,此时partition和消费者进程对应关系如下:
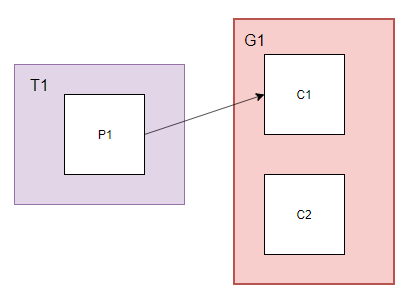
只有C1能接收到消息,C2不能接收到消息,即同一个partition内的消息只能被同一个组中的一个consumer消费。当消费者数量多于partition的数量时,多余的消费者空闲。
即:如果只有一个partition,在同一组启动多少个consumer都没用,partition的数量决定了此topic在同一组中被可被均衡的程度,例如partition=4,则可在同一组中被最多4个consumer均衡消费。
2.消费者少于分区数
opic:T2包含3个分区
Group: G2组中启动2个消费者
消费者数量为2小于分区数量3,此时partition和消费者进程对应关系如下:
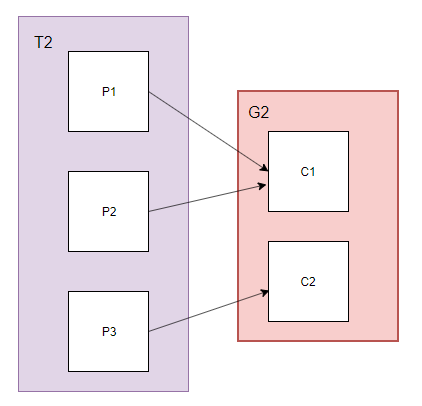
此时P1、P2对应C1,即多个partition对应一个消费者,C1接收到消息量是C2的两倍。
3.消费者等于partition
Topic:T3包含3个partition
Group: G3组中启动3个consumer
消费者数量为3等于partition数量3,此时partition和消费者进程对应关系如下:
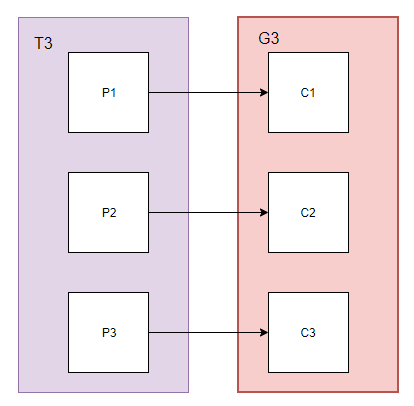
C1,C2,C3均分了T3的所有消息,即消息在同一个组之间的消费者之间均分了。
4.多个消费者组
Topic:T3包含3个partition
Group: G3组中启动3个consumer,G4组中启动1个consumer
此时partition和消费者进程对应关系如下:
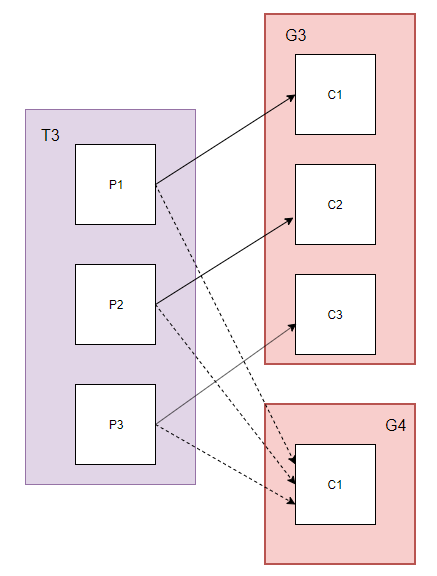
G3组的消费者均分消息;G4组的单个消费者消费所有消息。
同一个消息,会被每一个组都消费一次。
分区Rebalance(再均衡)
以下三种情况都会触发分区的重新分配,重新分配的过程叫Rebalance(再均衡)。
- 有新的消费者加入消费者群组
- 已有的消费者退出消费者群组
- 订阅的主题的分区发生变化
Rebalance给消费者群组带来了高可用性与伸缩性,但是在Rebalance期间,消费者无法读取消息,整个群组一小段时间不可用,而且当分区被重新分配给另一个消费者时,消费者当前的读取状态会丢失。
怎样提高消费速度?
场景1:消费者数量大于等于分区数量
此时无法提高速度,因为一个partition只能由消费者组的一个消费者去消费,增加消费者数量没用!
场景2:消费者数量大于分区数量
可以提高速度。多出来的分区会自动单独分出来给新消费者。
适合所有场景的方法:增加线程数量
增加单个消费者的消费线程数量可以提高消费速度,比如如下代码,指定2个线程去消费。
import com.artisan.springkafka.domain.MessageMock;
import com.artisan.springkafka.constants.TOPIC;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
@Slf4j
@Component
public class Consumer {
private static final String CONSUMER_GROUP_PREFIX = "MOCK-A" ;
@KafkaListener(topics = TOPIC.TOPIC ,
groupId = CONSUMER_GROUP_PREFIX + TOPIC.TOPIC,
concurrency = "2")
public void onMessage(MessageMock messageMock){
log.info("【接受到消息][线程ID:{} 消息内容:{}]", Thread.currentThread().getId(), messageMock);
}
}


请先 !