简介
本文介绍Redis的缓存穿透,包括:含义、原因、解决方案。
含义
说明
缓存穿透是指查询一个根本不存在的数据,缓存层没有命中,然后去查数据库(持久层),数据库(持久层)也没有命中。通常如果从存储层查不到数据则不写入缓存层。
比如:用户不断发起请求,通过文章的id来获取文章,如果这个id没有对应的数据,则每次都会请求到数据库。如果这个用户是攻击者,在请求过多时会导致数据库压力过大,严重会击垮数据库。
正常的操作流程
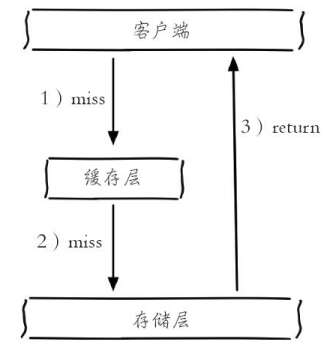
1) 缓存层不命中。
2) 存储层不命中,不将空结果写回缓存。
3) 返回空结果。
后果
缓存穿透将导致不存在的数据每次请求都要到存储层去查询,失去了缓存保护后端存储的意义。
缓存穿透问题可能会使后端数据库负载加大,由于很多数据库不具备高并发性,所以可能造成数据库宕掉。
通常可以在程序中分别统计总调用数、缓存层命中数、存储层命中数,如果发现大量存储层空命中,可能就是出现了缓存穿透问题。
穿透的原因
- 一些恶意攻击、 爬虫等造成大量空命中
- 自身业务代码或者数据出现问题
解决方案
方案1:缓存空对象
如图2所示,当第2步存储层不命中后,仍然将空对象保留到缓存层中,之后再访问这个数据将会从缓存中获取,这样就保护了后端数据源。
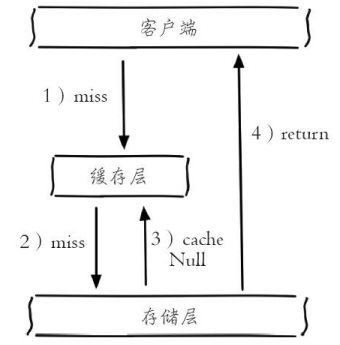
缓存空对象的两个问题
- 内存占用增加
- 说明:空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间(如果是攻击,问题更严重) 。
- 解决方案:给这个缓存设置一个较短的过期时间(比如5分钟),让其自动删除。
- 缓存层和存储层的数据会有一段时间窗口的不一致,可能会对业务有一定影响。
- 说明:假设过期时间设置为5分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储层数据的不一致
- 解决方案:将数据插入到存储层时,清除掉缓存层中的空对象。
代码实现(Jedis)
String get(String key) {
// 从缓存中获取数据
String cacheValue = cache.get(key);
// 缓存为空
if (StringUtils.isBlank(cacheValue)) {
// 从存储中获取
String storageValue = storage.get(key);
cache.set(key, storageValue);
// 如果存储数据为空, 需要设置一个过期时间(300秒)
if (storageValue == null) {
cache.expire(key, 60 * 5);
}
return storageValue;
} else {
// 缓存非空
return cacheValue;
}
}
方案2:布隆过滤器
布隆过滤器详见:Redis–布隆过滤器–使用/原理/实例 – 自学精灵
如图3所示,在访问缓存层和存储层之前,将存在的key用布隆过滤器提前保存起来,做第一层拦截。
查询的流程:
- 如果key在布隆过滤器中,去查询缓存
- 如果查询到,则返回缓存中的数据
- 如果没查询到,则穿透到db查询。
- 如果不在布隆器中
- 直接返回。
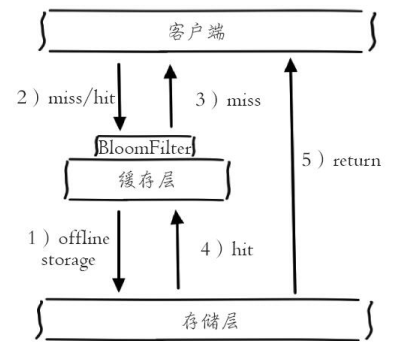
示例
比如:对于博客系统,一般是通过博客的id去访问。可以先将数据库中存在的博客的id放到布隆过滤器中,请求进来之后,如果id在布隆过滤器中,则允许通过id查到博客详情,否则直接返回空白的博客。在一定程度保护了存储层。
有关布隆过滤器的相关知识,可以参考: https://en.wikipedia.org/wiki/Bloom_filter。可以利用Redis的Bitmaps实现布隆过滤器,GitHub上已经开源了类似的方案,读者可以进行参考: https://github.com/erikdubbelboer/redis-lua-scaling-bloom-filter。
这种方法适用于数据命中不高、 数据相对固定、 实时性低(通常是数据集较大) 的应用场景,代码维护较为复杂,但是缓存空间占用少。
方案对比



请先 !