简介
本文介绍Redis的布隆过滤器的原理,优缺点,使用场景,实例。
布隆过滤器由n个Hash函数和一个二进制数组组成,主要用于判断一个元素是否在一个集合中。
布隆过滤器(英语:Bloom Filter)是 1970 年由布隆提出的。
布隆过滤器是Java后端面试中常见的问题。
原理
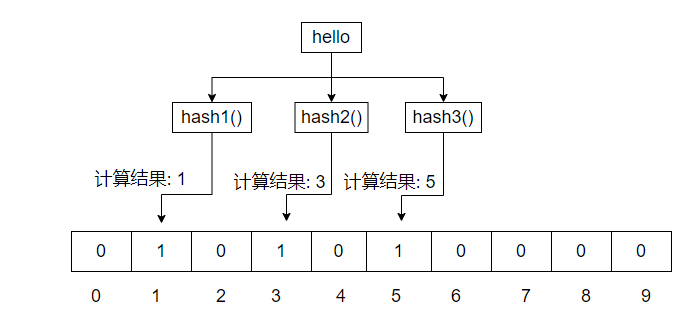
1.初始状态
一开始,二进制数组里是没有值的

2.存储操作
发来一个请求数据hello
对数据hello经过三次hash运算,分别得到三个值(假设1,3,5)。
在对应的二进制数组里,将下标为1,3,5的值置为1。
3.查询操作
发来一个请求数据hello
对数据hello经过三次hash运算,分别得到三个值(假设1,3,5)。
在二进制数组里,将下标为1,3,5的值取出来,如果都为1,则表示该数据已经存在。
4.删除操作
布隆过滤器很难进行删除操作。
如果hash2(hello)结果为3,hash2(world)结果也为3,那么如果删除了hello的值,就意味着world的值也会被其删除。
5.误判率
假设保存两个值,hello和world
hello对应的index(也就是hash计算后的值)为1,3,5
world对应的index(也就是hash计算后的值)为2,4,6
而此时来了一个值java,对应的index为1,4,5,查询得出结果:exist(java) = true,但其实,java这个数据并不存在,这就会产生一定的误判。
优缺点
优点
- 不需要存储元素本身,节省了大量的空间
- 查询速度很快
缺点
- 有一定的误识别率,不适合对误判率要求较高的场景。
- 无法删除数据
为了解决布隆过滤器不能删除元素的问题,布谷鸟过滤器横空出世。布谷鸟过滤器见:Redis-布谷鸟过滤器-使用/原理/实例 – 自学精灵
使用场景
- 存在的数据才去查数据库
- 业务系统:比如:对于博客系统,一般是通过博客的id去访问。可以先将数据库中存在的博客的id放到布隆过滤器中,请求进来之后,如果id在布隆过滤器中,则允许通过id查到博客详情,否则直接返回空白的博客。在一定程度保护了存储层。
- 数据库底层设计
- Google Bigtable,HBase 和 Cassandra 以及 Postgresql 使用BloomFilter来减少不存在的行或列的磁盘查找。
- 业务去重
- 判断用户是否阅读过某视频或文章。
- 比如抖音或头条,会导致一定的误判,但不会让用户看到重复的内容。
- 网页爬虫对 URL 去重,避免爬取相同的 URL 地址。
- 有用户访问时,想知道这个ip是不是第一次访问你的网站。
- 判断用户是否阅读过某视频或文章。
- 黑名单、白名单
- 反垃圾邮件(从大量的垃圾邮箱中判断是否存在某邮箱)
- Chrome浏览器使用了一个布隆过滤器识别恶意链接。比如:浏览器有时候会警告用户访问的网站可能是钓鱼网站。
- WEB拦截器
- 如果相同请求则拦截,防止被重复攻击。
- 用户第一次请求,将请求参数放入布隆过滤器中,当第二次请求时,先判断请求参数是否被布隆过滤器命中。可以提高缓存命中率。
- Squid 网页代理缓存服务器在 cache digests 中就使用了布隆过滤器。Google Chrome浏览器使用了布隆过滤器加速安全浏览服务。
- 如果相同请求则拦截,防止被重复攻击。
为什么用布隆过滤器这个数据结构?
以上这些场景有个共同的问题:如何查看一个东西是否在有大量数据的池子里面。
通常的做法有如下几种思路:
- 数组
- 链表
- 树、平衡二叉树、Trie
- Map (红黑树)
- 哈希表
上面这几种数据结构配合一些搜索算法是可以解决数据量不大的问题的,如果当集合里面的数据量非常大的时候,就会有问题。比如:
有500万条记录甚至1亿条记录?这个时候常规的数据结构的问题就凸显出来了。数组、链表、树等数据结构会存储元素的内容,一旦数据量过大,消耗的内存也会呈现线性增长,最终达到瓶颈。哈希表查询效率可以达到O(1)。但是哈希表需要消耗的内存依然很高。使用哈希表存储一亿 个垃圾 email 地址的消耗?哈希表的做法:首先,哈希函数将一个email地址映射成8字节信息指纹;考虑到哈希表存储效率通常小于50%(哈希冲突);因此消耗的内存:8 * 2 * 1亿 字节 = 1.6G 内存,普通计算机是无法提供如此大的内存。这个时候,布隆过滤器(Bloom Filter)就应运而生。
代码实现
已经有现成的布隆过滤器的实现了,不需要我们自己手写了。
单机版的布隆过滤器:Guava 的 BloomFilter;分布式的布隆过滤器:Redis的RedisBloom。
Guava
引入依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>23.0</version>
</dependency>
使用
public class GuavaBloomFilterDemo {
public static void main(String[] args) {
//后边两个参数:预计包含的数据量;允许的误差值
BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), 100000, 0.01);
for (int i = 0; i < 100000; i++) {
bloomFilter.put(i);
}
System.out.println(bloomFilter.mightContain(1));
System.out.println(bloomFilter.mightContain(2));
System.out.println(bloomFilter.mightContain(3));
System.out.println(bloomFilter.mightContain(100001));
//bloomFilter.writeTo();
}
}
Redis
简介
Redis 提供的 bitMap 可以实现布隆过滤器,但是需要自己设计映射函数和一些细节,这和我们自定义没啥区别。
Redis 官方提供的布隆过滤器到了 Redis 4.0 才正式登场。Redis 4.0 提供了插件功能,布隆过滤器作为一个插件加载到 Redis Server 中,给 Redis 提供了强大的布隆去重功能。
在已安装 Redis 的前提下,安装 RedisBloom,有两种方式:
直接编译进行安装
git clone https://github.com/RedisBloom/RedisBloom.git cd RedisBloom make #编译 会生成一个rebloom.so文件 redis-server --loadmodule /path/to/rebloom.so #运行redis时加载布隆过滤器模块 redis-cli # 启动连接容器中的 redis 客户端验证
使用Docker进行安装
docker pull redislabs/rebloom:latest # 拉取镜像 docker run -p 6379:6379 --name redis-redisbloom redislabs/rebloom:latest #运行容器 docker exec -it redis-redisbloom bash redis-cli
使用
布隆过滤器基本指令:
- bf.add 添加元素到布隆过滤器
- bf.exists 判断元素是否在布隆过滤器
- bf.madd 添加多个元素到布隆过滤器,bf.add 只能添加一个
- bf.mexists 判断多个元素是否在布隆过滤器
127.0.0.1:6379> bf.add user Tom (integer) 1 127.0.0.1:6379> bf.add user John (integer) 1 127.0.0.1:6379> bf.exists user Tom (integer) 1 127.0.0.1:6379> bf.exists user Linda (integer) 0 127.0.0.1:6379> bf.madd user Barry Jerry Mars 1) (integer) 1 2) (integer) 1 3) (integer) 1 127.0.0.1:6379> bf.mexists user Barry Linda 1) (integer) 1 2) (integer) 0
我们只有这几个参数,肯定不会有误判,当元素逐渐增多时,就会有一定的误判了,这里就不做这个实验了。
上面使用的布隆过滤器只是默认参数的布隆过滤器,它在我们第一次 add 的时候自动创建。
Redis 还提供了自定义参数的布隆过滤器,bf.reserve 过滤器名 error_rate initial_size
- error_rate:允许布隆过滤器的错误率,这个值越低过滤器的位数组的大小越大,占用空间也就越大
- initial_size:布隆过滤器可以储存的元素个数,当实际存储的元素个数超过这个值之后,过滤器的准确率会下降
但是这个操作需要在 add 之前显式创建。如果对应的 key 已经存在,bf.reserve 会报错
127.0.0.1:6379> bf.reserve user 0.01 100
(error) ERR item exists
127.0.0.1:6379> bf.reserve topic 0.01 1000
OK
Java操作
Redisson 和 lettuce 是可以使用布隆过滤器的,我们这里用 Redisson
public class RedissonBloomFilterDemo {
public static void main(String[] args) {
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("user");
// 初始化布隆过滤器,预计统计元素数量为55000000,期望误差率为0.03
bloomFilter.tryInit(55000000L, 0.03);
bloomFilter.add("Tom");
bloomFilter.add("Jack");
System.out.println(bloomFilter.count()); //2
System.out.println(bloomFilter.contains("Tom")); //true
System.out.println(bloomFilter.contains("Linda")); //false
}
}

请先 !