简介
本文介绍分布式项目中如何生成全局的唯一ID,通常是将其作为数据库的主键来使用的。
生成全局唯一ID有这几种方案:数据库、UUID、Redis、雪花算法、百度-UidGenerator、美团Leaf。一般情况下,推荐使用雪花算法,如果对时钟回拨有很高的要求,则推荐使用百度-UidGenerator、美团Leaf;不推荐使用数据库、UUID、Redis这三种方法。下边将详细进行讲述。
此技术也是Java后端面试中经常会问到的问题。
问题由来
传统的单体架构的时候,我们基本是单库,业务单表的结构。每个业务表的ID一般我们都是从1增,通过AUTO_INCREMENT=1设置自增起始值。
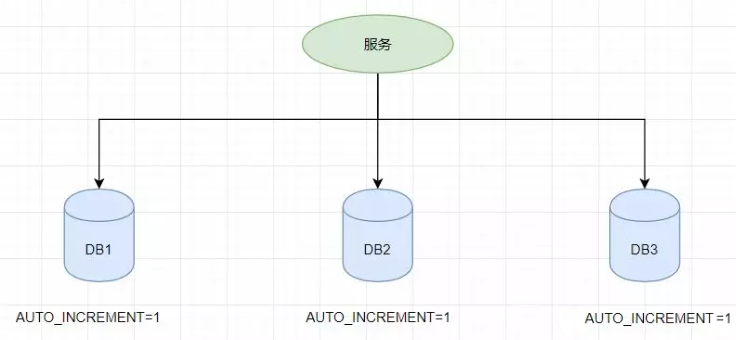
分布式数据库的分库分表中的数据需要唯一标识来找到对应的数据,还有其他的一些要求全局唯一的场景都是非常重要的。如果多个库都是用自增的方式,会造成ID冲突,如下图所示:如果第一个订单存储在 DB1 上则订单 ID 为1,当一个新订单又入库了存储在 DB2 上订单 ID 也为1。
全局的 unique ID 要满足以下需求:
- 保证生成的 ID 全局唯一
- 今后数据在多个 Shards 之间迁移不会受到 ID 生成方式的限制
- 生成的 ID 中最好能带上时间信息, 例如 ID 的前 k 位是 Timestamp, 这样能够直接通过对 ID 的前 k 位的排序来对数据按时间排序
- 生成的 ID 最好不大于 64 bits
- 生成 ID 的速度有要求. 例如, 在一个高吞吐量的场景中, 需要每秒生成几万个 ID (Twitter 最新的峰值到达了 143,199 Tweets/s, 也就是 10万+/秒)
- 整个服务最好没有单点
数据库生成
简介
由于分布式数据库的起始自增值一样所以才会有冲突的情况发生,那么我们将分布式系统中数据库的同一个业务表的自增ID设计成不一样的起始值,然后设置固定的步长,步长的值即为分库的数量或分表的数量。
以MySQL举例,利用给字段设置 auto_increment_increment和 auto_increment_offset来保证ID自增。
- autoincrementoffset:表示自增长字段从那个数开始,他的取值范围是1 .. 65535。
- autoincrementincrement:表示自增长字段每次递增的量,其默认值是1,取值范围是1 .. 65535。
示例
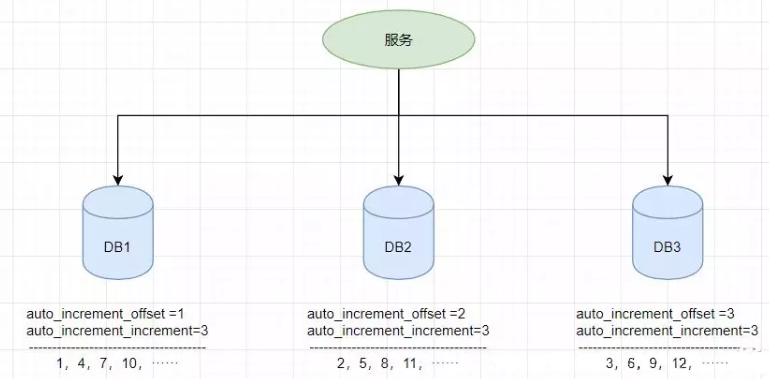
假设有三台机器,则DB1中order表的起始ID值为1,DB2中order表的起始值为2,DB3中order表的起始值为3,它们自增的步长都为3,则它们的ID生成范围如下图所示:
优缺点
优点:
- 依赖于数据库自身不需要其他资源;ID号单调自增,可以实现一些对ID有特殊要求的业务
缺点:
- 强依赖DB,当DB异常时整个系统不可用;
- 一致性难以保证:主从复制可增加可用性,但数据一致性在特殊情况下难保证:主从切换时的不一致可能会导致重复发号
- ID发号性能瓶颈限制在单台MySQL的读写性能
UUID
简介
UUID (Universally Unique Identifier),通用唯一识别码的缩写。UUID是由一组32位数的16进制数字所构成(16个字节,128位),所以UUID理论上的总数为 16^32=2^128,约等于 3.4 x 10^38。也就是说若每纳秒产生1兆个UUID,要花100亿年才会将所有UUID用完。
生成的UUID是由 8-4-4-4-12格式的数据组成,其中32个字符和4个连字符’ – ‘,一般我们使用的时候会将连字符删除 uuid.toString().replaceAll(“-“,””)。
目前UUID的产生方式有5种版本,每个版本的算法不同,应用范围也不同。
- 随机UUID
- 根据随机数,或者伪随机数生成UUID。
- 这种UUID产生重复的概率是可以计算出来的,重复的可能性可以忽略不计,因此该版本也是被经常使用的版本。
- JDK有这个版本的实现:UUID.randomUUID()
- 基于时间的UUID
- 一般是通过当前时间,随机数,和本地Mac地址来计算出来,可以通过 org.apache.logging.log4j.core.util包中的 UuidUtil.getTimeBasedUuid()来使用或者其他包中工具。
- 由于使用了MAC地址,因此能够确保唯一性,但是同时也暴露了MAC地址,私密性不够好。
- 基于名字的UUID(MD5)
- 基于名字的UUID通过计算名字和名字空间的MD5散列值得到。
- 保证了:相同名字空间中不同名字生成的UUID的唯一性;不同名字空间中的UUID的唯一性;相同名字空间中相同名字的UUID重复生成是相同的。
- JDK有这个版本的实现:UUID.nameUUIDFromBytes(nbyte)
- 基于名字的UUID(SHA1)
- 和基于名字的UUID算法类似,只是散列值计算使用SHA1(Secure Hash Algorithm 1)算法。
- DCE安全的UUID。
- DCE(Distributed Computing Environment)安全的UUID和基于时间的UUID算法相同,但会把时间戳的前4位置换为POSIX的UID或GID。这个版本的UUID在实际中较少用到。
示例
Java中 JDK自带的 UUID产生方式就是版本4根据随机数生成的 UUID 和版本3基于名字的 UUID。
public static void main(String[] args) {
//获取一个根据随机字节数组的UUID。
UUID uuid = UUID.randomUUID();
System.out.println(uuid.toString().replaceAll("-",""));
//获取一个基于名称根据指定的字节数组的UUID。
byte[] nbyte = {10, 20, 30};
UUID uuidFromBytes = UUID.nameUUIDFromBytes(nbyte);
System.out.println(uuidFromBytes.toString().replaceAll("-",""));
}
得到结果:
59f51e7ea5ca453bbfaf2c1579f09f1d 7f49b84d0bbc38e9a493718013baace6
优点
- 不依赖第三方
缺点
- 不利于存储:UUID太长,16字节128位,是长度为32的字符串。
- 信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露,暴露使用者的位置。
- 对MySQL索引不利: 如果作为数据库主键,在InnoDB引擎下,UUID的无序性可能会引起数据位置频繁变动,严重影响性能,可以查阅 Mysql 索引原理 B+树的知识。
Redis
简介
当使用数据库来生成ID的性能达不到要求时,我们可以尝试引入中间件来生成ID,比如常见的Mongodb、Redis等,这里我们介绍一下Redis生成ID的方案。
Redis实现分布式唯一ID主要是通过提供像 INCR 和 INCRBY 这样的自增原子命令,由于Redis自身的单线程的特点所以能保证生成的 ID 肯定是唯一有序的。(可以用redis的RedisAtomicLong生成自增的ID值)。
实现
@Autowired
private RedisTemplate<String,Serializable> mRedisTemp;
/**
* 获取自增长ID
* @param key
* @return
*/
public long generate(String key) {
RedisAtomicLong counter = new RedisAtomicLong(key,mRedisTemp.getConnectionFactory());
return counter.incrementAndGet();
}
/**
* 获取有过期时间的自增长ID
* @param key
* @param expireTime
* @return
*/
public long generate(String key,Date expireTime) {
RedisAtomicLong counter = new RedisAtomicLong(key, mRedisTemp.getConnectionFactory());
counter.expireAt(expireTime);
return counter.incrementAndGet();
}
/**
* 获取能按固定步长增长的有过期时间的ID
* @param key
* @param increment
* @return
*/
public long generate(String key,int increment,Date expireTime) {
RedisAtomicLong counter = new RedisAtomicLong(key, mRedisTemp.getConnectionFactory());
counter.expireAt(expireTime);
return counter.addAndGet(increment);
}
优点
- 性能好: 因为是用Redis来生成id,不依赖数据库,而且性能优于数据库。
- ID天然有序: 对分页或者需要排序的结果很方便。
缺点
- 若Redis没有做持久化,然后重启了Redis,会导致ID重复。
- 需使用Redis
总结
- 单机存在性能瓶颈,无法满足高并发的业务需求,所以可以采用集群的方式来实现。集群的方式又会涉及到和数据库集群同样的问题,所以也需要设置分段和步长来实现。
- 为了避免长期自增后数字过大可以通过与当前时间戳组合起来使用,另外为了保证并发和业务多线程的问题可以采用 Redis + Lua的方式进行编码,保证安全。
分布式中Redis的使用性很普遍,所以如果其他业务已经引进了Redis集群,则完全可以使用Redis来实现。可以获得系统的需求,又方便维护
雪花算法
百度UidGenerator
见:分布式-雪花算法改进版-百度的UidGenerator – 自学精灵

请先 !