简介
本文介绍Java中的HashMap如何进行线程安全的操作、为什么HashMap不是线程安全的。
这几个问题也是Java后端面试中经常问到的问题。
HashMap线程安全的操作方法
线程安全Map的三种方法
| 方法 | 示例 | 原理 | 性能 |
| Hashtable | Map<String, Object> map = new Hashtable<>(); | synchronized修饰get/put方法。 方法级阻塞,只能同时一个线程操作get或put | 很差。 |
| Collections.synchronizedMap | Map<String, Object> map = Collections.synchronizedMap( new HashMap<String, Object>()); | 所有方法都使用synchronized修饰。 | 很差。 和Hashtable差不多。 |
| JUC中的ConcurrentHashMap | Map<String, Object> map = new ConcurrentHashMap<>(); | 每次只给一个桶(数组项)加锁。 | 很好。 |
Hashtable线程安全的原理
所有方法都用了synchronized修饰
public synchronized V get(Object key) {
// ...
}
public synchronized V put(K key, V value) {
// ...
}
public synchronized int size() {
return count;
}
Collections.synchronizedMap线程安全的原理
此方法返回的是:Collections的静态内部类SynchronizedMap
内部有个mutex对象,对它加锁。
final Object mutex;
public V get(Object key) {
synchronized (mutex) {return m.get(key);}
}
public V put(K key, V value) {
synchronized (mutex) {return m.put(key, value);}
}
public int size() {
synchronized (mutex) {return m.size();}
}
HashMap为什么线程不安全
简介
| 项 | JDK7 | JDK8 |
| 多线程的结果 | 数据覆盖(场景:多线程put+put) 读出为null(场景:多线程扩容,put+get) 死循环 (场景:多线程扩容(头插法导致)) | 数据覆盖(场景:多线程put) 读出为null(场景:多线程扩容,put+get) 不会发生: 死循环(因为是尾插法) |
JDK7
数据覆盖
与JDK8相似,见下方。
读出为null
与JDK8相似,见下方。
死循环
简介
多线程扩容时,可能死循环。
原因:扩容后链表中的节点在新的hash桶使用头插法插入。新的hash桶会倒置原hash桶中的单链表,那么在多个线程同时扩容的情况下就可能导致产生一个存在闭环的单链表,从而导致死循环。
因为如果两个线程同时发现 HashMap 需要扩容了,它们会同时扩容。在扩容的过程中,存储在链表中的元素的次序会反过来。因为移动到新的 bucket 位置的时候,HashMap 并不会将元素放在链表的尾部,而是放在头部。这是为了避免尾部遍历(tail traversing)。如果条件竞争发生了,那么就死循环了。
HashMap 的容量是有限的。当经过多次元素插入,使得 HashMap 达到一定饱和度时,Key 映射位置发生冲突的几率会逐渐提高。这时候, HashMap 需要扩展它的长度,也就是进行Resize。
扩容:创建一个新的 Entry 空数组,长度是原数组的2倍
rehash:遍历原 Entry 数组,把所有的 Entry 重新 Hash 到新数组
源码分析
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
//头插法(JDK1.7)
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
transfer:
- 对索引数组中的元素遍历
- 对链表上的每一个节点遍历:用 next 取得要转移那个元素的下一个,将 e 转移到新 Hash 表的头部,使用头插法插入节点。
- 循环2,直到链表节点全部转移
- 循环1,直到所有索引数组全部转移
可发现转移的时候是逆序的。假如转移前链表顺序是1->2->3,那么转移后就会变成3->2->1。这时候就有点头绪了,死锁问题不就是因为1->2的同时2->1造成的吗?所以,HashMap 的死锁问题就出在这个transfer()函数上。
单线程:rehash
单线程情况下,rehash不会出现任何问题:
- 假设hash算法就是最简单的 key mod table.length(也就是数组的长度)。
- 最上面的是old hash 表,其中的Hash表的 size = 2, 所以 key = 3, 7, 5,在 mod 2以后碰撞发生在 table[1]
- 接下来的三个步骤是 Hash表 扩容到4,并将所有的 <key,value> 进行rehash并放到到新 Hash 表的过程
如图所示:头插法

多线程:rehash
为了思路更清晰,我们只将关键代码展示出来
while(null != e) {
Entry<K,V> next = e.next;
e.next = newTable[i];
newTable[i] = e;
e = next;
}
Entry<K,V> next = e.next;—因为是单链表,如果要转移头指针,一定要保存下一个结点,不然转移后链表就丢了
e.next = newTable[i]; —e 要插入到链表头,先用 e.next 指向新 Hash 表第一个元素(加到链表最后比较慢,所以加到头)
newTable[i] = e; —现在新 Hash 表的头指针仍然指向 e 没转移前的第一个元素,所以需要将新 Hash 表的头指针指向 e
e = next —转移 e 的下一个结点
Step1:
线程1:在执行到Entry<K,V> next = e.next;之后,cpu 时间片用完了,被调度挂起,这时线程1的 e 指向 节点A,线程1的 next 指向节点B。
线程2:继续执行。
此时,状态如下图:
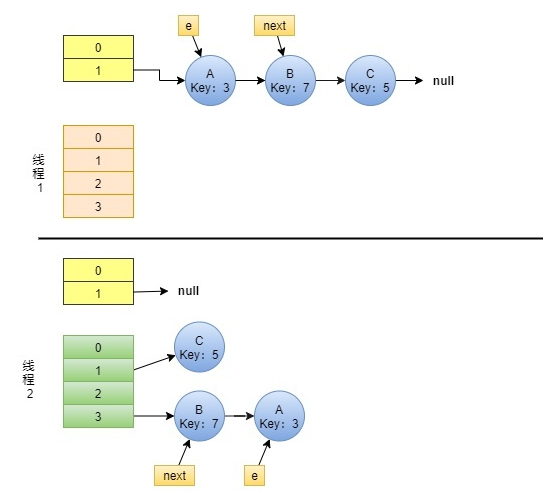
Step2
线程 1 被调度回来执行。
- 先是执行 newTalbe[i] = e;
- 然后是e = next,导致了e指向了节点B,
- 而下一次循环的next = e.next导致了next指向了节点A。
此时,状态如下图所示:
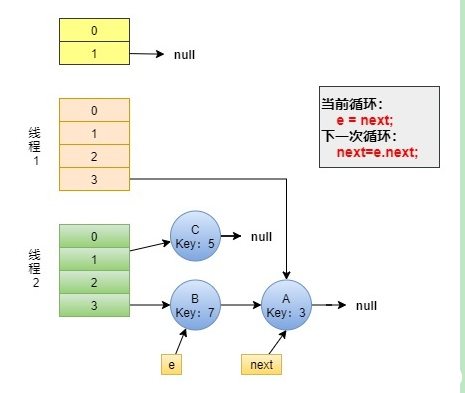
Step3
线程1 接着工作。把节点B摘下来,放到newTable[i]的第一个,然后把e和next往下移。
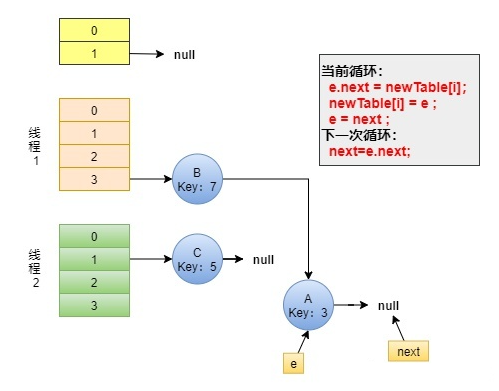
Step4: 出现环形链表
e.next = newTable[i] 导致A.next 指向了 节点B,此时的B.next 已经指向了节点A,出现环形链表。
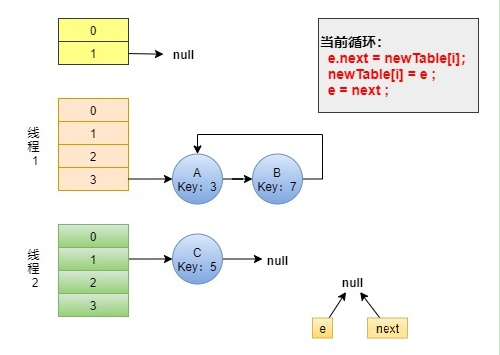
如果get一个在此链表中不存在的key时,就会出现死循环了。如 get(11)时,就发生了死循环。
JDK8
数据覆盖
简介
多线程同时执行 put 操作,如果计算出来的索引位置是相同的(即:哈希冲突),那会造成前一个 key 被后一个 key 覆盖,从而导致元素的丢失。
源码分析
put(K key, V value) //HashMap
putVal(hash(key), key, value, false, true) //HashMap
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) // 1
tab[i] = newNode(hash, key, value, null);
else { // 2
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold) // 3
resize();
afterNodeInsertion(evict);
return null;
}
1:判断是否出现hash碰撞。通过hash值计算在hash表中的位置,并将此位置上的元素赋值给p,若为空则new一个新的node放到此位置
2:若hash表当前位置已经存在元素,追加此元素
1.哈希冲突导致线程不安全
假设两个线程A、B都在进行put操作,并且hash函数计算出的插入下标是相同的。当线程A执行完“// 1”处的代码后由于时间片耗尽导致被挂起,而线程B得到时间片后在该下标处插入了元素,完成了正常的插入,然后线程A获得时间片,由于之前已经进行了hash碰撞的判断,所有此时不会再进行判断,而是直接进行插入,这就导致了线程B插入的数据被线程A覆盖了,从而线程不安全。
2.大小计算导致线程不安全
“// 3”处有个++size。线程A、B,这两个线程同时进行put操作时,假设当前HashMap的zise大小为10,当线程A执行到“// 3”处时,从主内存中获得size的值为10后准备进行+1操作,但是由于时间片耗尽只好让出CPU,线程B快乐的拿到CPU还是从主内存中拿到size的值10进行+1操作,完成了put操作并将size=11写回主内存,然后线程A再次拿到CPU并继续执行(此时size的值仍为10),当执行完put操作后,还是将size=11写回内存,此时,线程A、B都执行了一次put操作,但是size的值只增加了1,所有说还是由于数据覆盖导致了线程不安全。
读出为null
简介
线程1进行put时,因为元素个数超出threshold而导致扩容(new一个新的hash表),线程2此时get,有可能导致读出为null(新hash表还没有值)。此问题在JDK 1.7和 JDK 1.8 中都存在。
源码分析
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; // 1
table = newTab; // 2
//省略rehash的代码
return newTab;
}
在代码“// 1”位置,用新计算的容量new了一个新的hash表,“// 2”将新创建的空hash表赋值给实例变量table。
此时实例变量table是空的,如果此时另一个线程执行get,就会get出null。
不会死循环
在JDK 1.8由于使用的是尾插法,不会导致单链表的倒置,所以扩容的时候不会导致死循环。
ConcurrentSkipListMap
简介
ConcurrentSkipListMap是在JDK 1.6中新增的,为了对高并发场景下的有序Map提供更好的支持,它有几个特点:
- 适合用于高并发场景
- key是有序的
- 基于跳表结构(Skip List)实现,查询、插入、删除的时间复杂度都是 O(logn)。
- key和value都不能为null



请先 !