简介
本文介绍MySQL查询语法(命令)的使用。包括:基本查询、运算条件、排序、分页、分组、联结、组合、子查询、distinct等。
SQL查询语句官网:MySQL :: MySQL 8.0 Reference Manual :: 13.2.10 SELECT Statement
基本查询
| 操作 | 命令 | 示例/说明 |
| 查询所有列 | SELECT * FROM 表名 | SELECT * FROM table_name; |
| 查询指定列 | SELECT 列1,列2,…FROM 表名; | SELECT id,name FROM table_name; |
| 使用 AS 给字段起别名 | SELECT id AS 序号, name AS 名字, gender AS 性别 FROM students; | AS 不写也可以,跟写AS 一样效果。 |
| 通过 AS 给表起别名 | SELECT col1,col2 FROM table_name AS xxx | SELECT s.id,s.name,t.gender FROM students AS s, teachers AS t; |
SELECT子句必须遵循的顺序(从左到右对应从上到下)
| 子句 | 说明 | 是否必须使用 |
| SELECT | 要返回的列或表达式 | 是 |
| FROM | 从中检索数据的表 | 仅在从表选择数据时使用 |
| WHERE | 行级过滤 | 否 |
| GROUP BY | 分组说明 | 仅在按组计算聚集时使用 |
| HAVING | 组级过滤 | 否 |
| ORDER BY | 输出排序顺序 | 否 |
| LIMIT | 要检索的行数 | 否 |
运算条件
WHERE 后面支持多种运算符,进行条件的处理
比较运算符、逻辑运算符、模糊查询、范围查询、空判断
| 运算符 | 详情 | 示例 | |
| 比较 | 等于: = 大于: > 大于等于: >= 小于: < 小于等于: <= 不等于: != 或 <> | 例:查询编号大于3的学生: SELECT * FROM students WHERE id > 3; 例:查询编号不大于4的学生: SELECT * FROM students WHERE id <= 4; 例:查询姓名不是“黄蓉”的学生: SELECT * FROM students WHERE name != ‘黄蓉’; 例:查询没被删除的学生: SELECT * FROM students WHERE is_delete=0; | |
| 逻辑 | AND,OR,NOT //sql 会首先执行 AND 条件,再执行 OR 语句。除非加括号 | 例:查询编号大于3的女同学: SELECT * FROM students WHERE id > 3 AND gender=0; 例:查询编号小于4或没被删除的学生: SELECT * FROM students WHERE id < 4 OR is_delete=0; 例:查询编号小于4,或大于10而且没被删除的学生: SELECT * FROM students WHERE id < 4 or id > 10 AND is_delete=0; 例:查询编号小于4或大于10,而且没被删除的学生: SELECT * FROM students WHERE (id < 4 or id > 10) AND is_delete=0; | |
| 模糊查询 | LIKE % 任意多个任意字符 _ 一个任意字符 | 例:查询姓黄的学生: SELECT * FROM students WHERE name LIKE ‘黄%’; 例:查询姓黄并且“名”是一个字的学生:SELECT * FROM students WHERE name LIKE ‘黄_’; 例:查询姓黄或叫靖的学生:SELECT * FROM students WHERE name LIKE ‘黄%’ OR name LIKE ‘%靖’; | |
| 范围查询 | 分为 连续/非连续 范围查询 IN:非连续 BETWEEN … AND …:连续 (包含端点) | 例:查询编号是1或3或8的学生: SELECT * FROM students WHERE id in(1,3,8); 例:查询编号为3至8的学生: SELECT * FROM students WHERE id BETWEEN 3 AND 8; 例:查询编号是3至8的男生: SELECT * FROM students WHERE (id BETWEEN 3 AND 8) AND gender=1; | |
| 空判断 | 判断为空/非空 注意: null与’’是不同的 | 例:查询没有填写身高的学生:SELECT * FROM students WHERE height IS NULL; 例:查询填写了身高的学生: SELECT * FROM students WHERE height IS NOT NULL; 例:查询填写了身高的男生: SELECT * FROM students WHERE height IS NOT NULL AND gender=1; | |
优先级
优先级由高到低的顺序为:小括号 > NOT > 比较运算符 > 逻辑运算符
AND比OR先运算,如果同时出现并希望先算or,需要结合()使用
排序
排序查询语法
SELECT * FROM 表名 ORDER BY 列1 ASC|DESC[,列2 ASC|DESC,…]
语法说明
- 将行数据按照列1进行排序,如果某些行 列1 的值相同时,则按照 列2 排序,以此类推
- asc:从小到大排列,即升序;desc从大到小排序,即降序
- 默认按照列值从小到大排列(即asc关键字)
示例
- 查询未删除男生信息,按学号降序
- SELECT * FROM students WHERE gender=1 and is_delete=0 ORDER BY id desc;
- 查询未删除学生信息,按名称升序
- SELECT * FROM students WHERE is_delete=0 ORDER BY name;
- 显示所有的学生信息,先按照年龄从大–>小排序,当年龄相同时 按照身高从高–>矮排序
- SELECT * FROM students ORDER BY age desc,height desc;
分页
语法
SELECT * FROM 表名 LIMIT start,count
说明
- 从start开始,获取count条数据,start默认值为0。
- 需要获取数据的前n条的时候可以直接写上 xxx limit n;
- 在sql语句中limit后不可以直接加公式
示例
- 查询前3行男生信息
- SELECT * FROM students WHERE gender=1 LIMIT 0,3;
- 每页显示m条,显示第n页
- SELECT * FROM students WHERE deleted LIMIT (n-1)*m,m
分组
语法
SELECT xxx GROUP BY { <列名> | <表达式> | <位置> } [ASC | DESC]
示例
每个厂家提供多种商品。表结构如下:
| 字段名 | 字段含义 |
| vendor_id | 厂家id |
| product_id | 商品id |
| product_count | 该商品的数量 |
例1:按厂家id去重,每个厂家id只返回一条数据
SELECT * FROM products GROUP BY vendor_id
例2:查询每个厂家的商品种类的数量。
SELECT vendor_id, COUNT(*) AS number_product_type FROM products GROUP BY vendor_id
例3:查询每个厂家的商品种类的数量以及每个厂家所有商品的数量总和
SELECT vendor_id, COUNT(*), SUM(product_count) AS number_product_type FROM products GROUP BY vendor_id
例4:查询每个厂家的每种商品的商品数量。
SELECT vendor_id, product_id, COUNT(*) AS number_product FROM products GROUP BY vendor_id, product_id
注意事项
- GROUP BY子句可以包含任意数目的列。这使得能对分组进行嵌套,为数据分组提供更细致的控制。
- 如果在GROUP BY子句中嵌套了分组,数据将在最后规定的分组上进行汇总。换句话说,在建立分组时,指定的所有列都一起计算(所以不能从个别的列取回数据)。
- GROUP BY子句中列出的每个列都必须是检索列或有效的表达式(但不能是聚集函数)。如果在SELECT中使用表达式,则必须在GROUP BY子句中指定相同的表达式。不能使用别名。
- 除聚集计算语句外, SELECT语句中的每个列都必须在GROUP BY子句中给出。
- 如果分组列中具有NULL值,则NULL将作为一个分组返回。如果列中有多行NULL值,它们将分为一组。
- GROUP BY子句必须出现在WHERE子句之后, ORDER BY子句之前
高级用法
| 语句 | 作用 |
| GROUP BY + HAVING | HAVING 条件表达式:用来过滤分组结果。 HAVING和WHERE类似,但HAVING用于过滤GROUP BY后的数据,而WHERE用于过滤GROUP BY以前的单行数据。 示例:厂家提供多种商品,商品表中有厂家id。查出商品数量大于2的每个厂家的商品种类数量。 SELECT vend_id, COUNT(*) AS num_prods FROM products GROUP BY vend_id HAVING COUNT(*) > 2 |
| GROUP BY + GROUP_CONCAT() | GROUP_CONCAT(字段名):根据分组结果,放置每一个分组中某字段的集合 |
| GROUP BY + 聚合函数 | 通过GROUP_CONCAT()的启发,通过集合函数来对这个值的集合做一些操作 |
| GROUP BY + WITH ROLLUP | WITH ROLLUP的作用是:在最后新增一行,来记录当前表中该字段对应的操作结果,一般是汇总结果,比如把某一列求和。 |
联结
语法
SELECT * FROM 表1 INNER/OUTER/LEFT/RIGHT JOIN 表2 ON 表1.列 运算符 表2.列
对于外联结 outer关键字可以省略
示例
- 使用内连接查询班级表与学生表
- SELECT * FROM students INNER JOIN classes ON students.cls_id = classes.id;
- 使用内连接查询班级表与学生表(多个条件)
- SELECT * FROM students INNER JOIN classes ON students.cls_id = classes.id AND students.delete_flag = 0 AND classes.delete_flag = 0;
- 使用左连接查询班级表与学生表(此处使用了AS为表起别名,目的是编写简单)
- SELECT * FROM students AS s LEFT JOIN classes AS c ON s.cls_id = c.id;
- 使用右连接查询班级表与学生表
- SELECT * FROM students AS s RIGHT JOIN classes AS c ON s.cls_id = c.id;
- 查询学生姓名及班级名称
- SELECT s.name,c.name FROM students AS s INNER JOIN classes AS c ON s.cls_id = c.id;
组合
如果union要与limit或者order by一起使用,查询子句需要用括号,例如:
(SELECT * FROM t_visitor_record WHERE substr(t_visitor_record.create_time, 12, 8) BETWEEN '00:00:00' AND '11:59:59' ORDER BY t_visitor_record.create_time) UNION (SELECT * FROM t_visitor_record WHERE substr(t_visitor_record.create_time, 12, 8) BETWEEN '12:00:00' AND '23:59:59' ORDER BY t_visitor_record.create_time)
union与union all
union会去重,如果在一个条件中返回了,下一个条件中就算是有也不会返回。union all不会去重, 如果在一个条件中返回了,下一个如果有重复的,也会返回。
子查询
定义
一个 select 语句中,嵌入另外一个 select 语句, 被嵌入的 select 语句称为子查询语句,外部select语句则称为主查询。
主查询和子查询的关系
- 子查询是嵌入到主查询中
- 子查询是辅助主查询的,要么充当条件,要么充当数据源
- 子查询是可以独立存在的语句,是一条完整的 select 语句
不相关子查询
分为三种:标量子查询,列级子查询,行级子查询。
标量子查询
示例:查询班级学生平均年龄
先查询班级学生平均年龄,再查询大于平均年龄的学生
SELECT * FROM students WHERE age > (SELECT AVG(age) FROM students);
列级子查询
示例:查询学生所在班级的所有班级名字
先找出学生表中所有的班级 id,再找出班级表中对应的名字
SELECT name FROM classes WHERE id IN (SELECT cls_id FROM students);
行级子查询
示例1:查找班级年龄最大而且身高最高的学生。
SELECT * FROM students WHERE (height, age) = (SELECT MAX(height), MAX(age) FROM students);
示例2:查询所有年龄为20的学生的姓名和身高(本处刻意用这个方法,实际不需要)
SELECT * FROM students WHERE (name, height) = (SELECT * FROM students WHERE age = 20);
示例3:查找班级有相同的身高和年龄的学生的所有数据。
SELECT * FROM students WHERE (height, age) IN (SELECT height, age FROM students GROUP BY height, age HAVING COUNT(*) > 1);
相关子查询
| 子查询 | 步骤 | 示例 |
| 作为计算字段 | 查找班里每个学生的名字及成绩。 步骤: 先从t_student查找所有学生 再统计每个学生的成绩(t_grade) | SELECT name, (SELECT score FROM t_grade WHERE t_grade.student_id = t_student.id) FROM t_student |
distinct
表的数据
表A:
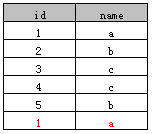
表B:
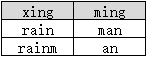
1.作用于单列
SELECT DISTINCT name FROM A
执行后结果如下:

2.作用于多列
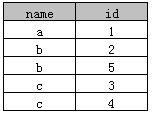
示例2.1
SELECT DISTINCT name, id FROM A
执行后结果如下:
示例2.2
SELECT DISTINCT xing, ming FROM B
返回如下结果:
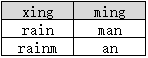
返回的结果为两行,这说明distinct并非是对xing和ming两列“字符串拼接”后再去重的,而是分别作用于了xing和ming列。
3.COUNT统计
查表中name去重后的数目, SQL Server支持,而Access不支持
SELECT COUNT(DISTINCT name) FROM A;
count是不能统计多个字段的,下面的SQL在SQL Server和Access中都无法运行。
SELECT COUNT(DISTINCT name, id) FROM A;
若想使用,请使用嵌套查询,如下:
SELECT COUNT(*) FROM (SELECT DISTINCT xing, name FROM B) AS M;
4.distinct必须放在开头
select id, distinct name from A; --会提示错误,因为distinct必须放在开头
5.其他
distinct语句中select显示的字段只能是distinct指定的字段,其他字段是不可能出现的。例如,假如表A有“备注”列,如果想获取distinc name,以及对应的“备注”字段,想直接通过distinct是不可能实现的。但可以通过其他方法实现。
NOT EXISTS
例如:查询在t_user表里存在但在t_user_detail不存在的数据
SELECT
t_user.*
FROM
t_user
WHERE
t_user.`username` = 'aaa'
AND t_user.`delete_flag` = '0'
AND EXISTS (
SELECT
1
FROM
t_user_detail
WHERE
t_user.id = t_user_detail.user_id
AND t_user_detail.delete_flag = '0'
)

请先 !