简介
本文介绍Redis的Cluster集群收缩的过程(原理)。
流程概述
收缩集群意味着缩减规模, 需要从现有集群中安全下线部分节点。 安全下线节点流程如下图所示。
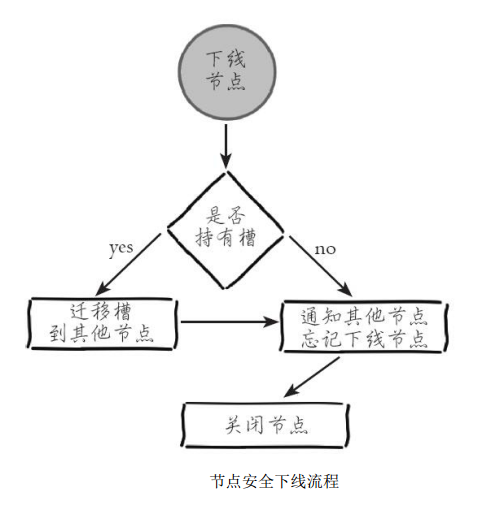
流程说明:
- 首先需要确定下线节点是否有负责的槽, 如果是, 需要把槽迁移到其他节点, 保证节点下线后整个集群槽节点映射的完整性。
- 当下线节点不再负责槽或者本身是从节点时, 就可以通知集群内其他节点忘记下线节点, 当所有的节点忘记该节点后可以正常关闭。
1.下线迁移槽
下线节点需要把自己负责的槽迁移到其他节点, 原理与之前节点扩容的迁移槽过程一致。 例如我们把6381和6384节点下线, 节点信息如下:
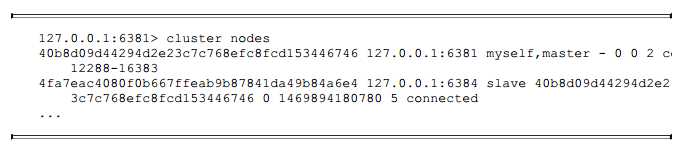
6381是主节点, 负责槽(12288-16383) , 6384是它的从节点, 如图10-26所示。 下线6381之前需要把负责的槽迁移到其他节点。
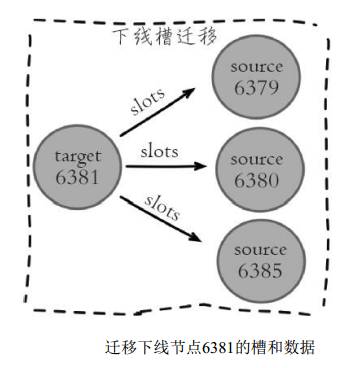
收缩正好和扩容迁移方向相反, 6381变为源节点, 其他主节点变为目标节点, 源节点需要把自身负责的4096个槽均匀地迁移到其他主节点上。 这里直接使用redis-trib.rb reshard命令完成槽迁移。 由于每次执行reshard命令只能有一个目标节点, 因此需要执行3次reshard命令, 分别迁移1365、 1365、1366个槽, 如下所示:
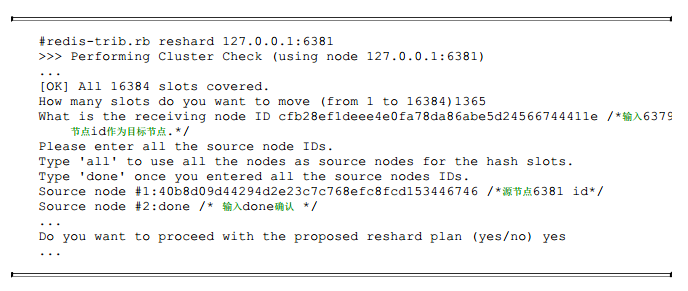
槽迁移完成后, 6379节点接管了1365个槽12288~13652, 如下所示:
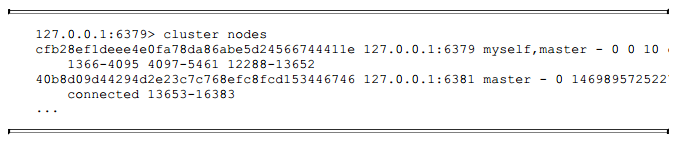
继续把1365个槽迁移到节点6380:
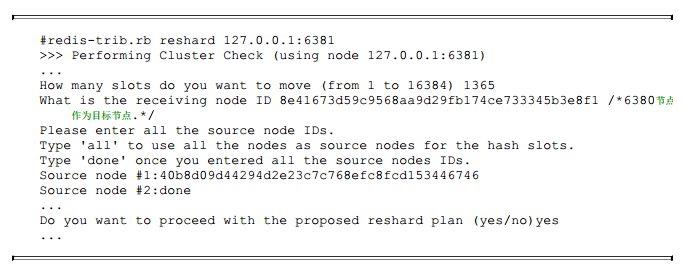
完成后, 6380节点接管了1365个槽13653~15017, 如下所示:
127.0.0.1:6379> cluster nodes
40b8d09d44294d2e23c7c768efc8fcd153446746 127.0.0.1:6381 master - 0 1469896123295 2
connected 15018-16383
8e41673d59c9568aa9d29fb174ce733345b3e8f1 127.0.0.1:6380 master - 0 1469896125311 11
connected 6827-10922 13653-15017
...
把最后的1366个槽迁移到节点6385中, 如下所示:
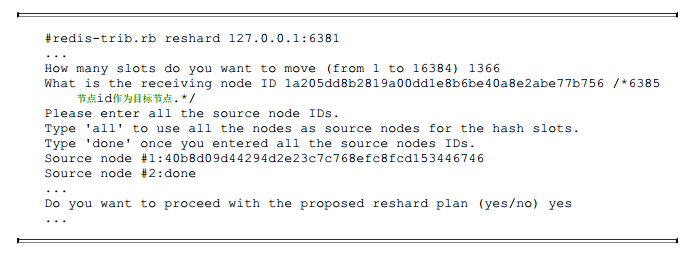
到目前为止, 节点6381所有的槽全部迁出完成, 6381不再负责任何槽。状态如下所示:
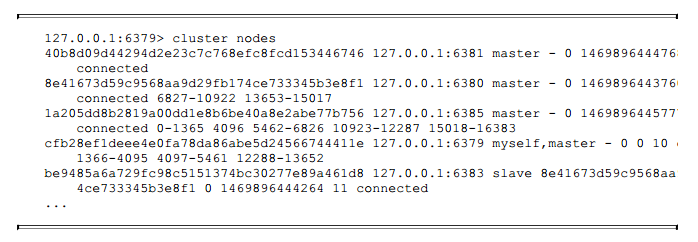
下线节点槽迁出完成后, 剩下的步骤需要让集群忘记该节点。
2.忘记节点
由于集群内的节点不停地通过Gossip消息彼此交换节点状态, 因此需要通过一种健壮的机制让集群内所有节点忘记下线的节点。 也就是说让其他节点不再与要下线节点进行Gossip消息交换。 Redis提供了cluster616forget{downNodeId}命令实现该功能, 如下图所示。
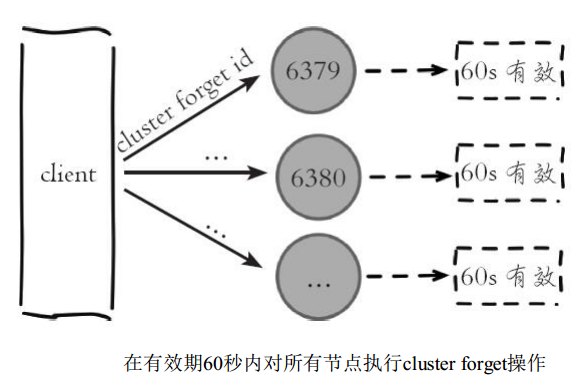
在有效期60秒内对所有节点执行cluster forget操作当节点接收到cluster forget{down NodeId}命令后, 会把nodeId指定的节点加入到禁用列表中, 在禁用列表内的节点不再发送Gossip消息。 禁用列表有效期是60秒, 超过60秒节点会再次参与消息交换。 也就是说当第一次forget命令发出后, 我们有60秒的时间让集群内的所有节点忘记下线节点。
线上操作不建议直接使用cluster forget命令下线节点, 需要跟大量节点命令交互, 实际操作起来过于繁琐并且容易遗漏forget节点。 建议使用redistrib.rb del-node{host: port}{downNodeId}命令, 内部实现的伪代码如下:
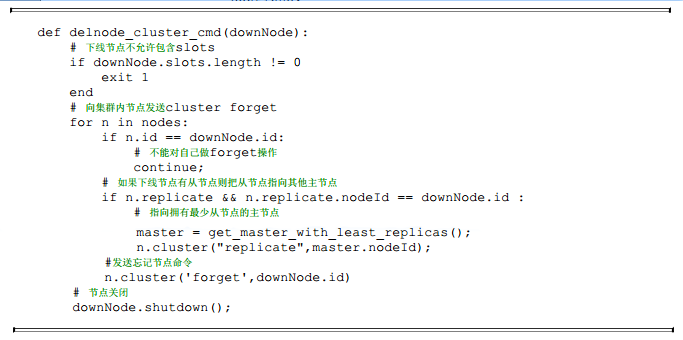
从伪代码看出del-node命令帮我们实现了安全下线的后续操作。 当下线主节点具有从节点时需要把该从节点指向到其他主节点, 因此对于主从节点都下线的情况, 建议先下线从节点再下线主节点, 防止不必要的全量复制。对于6381和6384节点下线操作, 命令如下:

节点下线后确认节点状态:
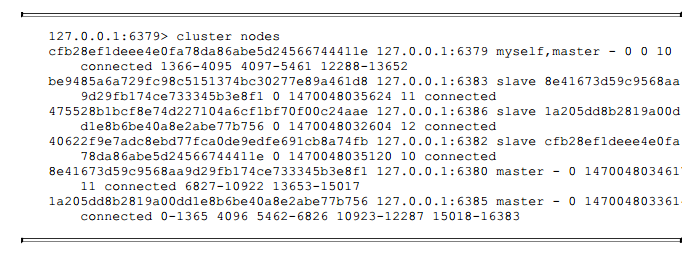
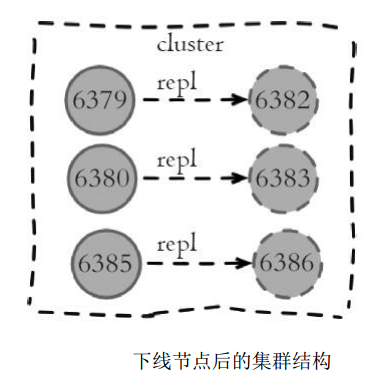
集群节点状态中已经不包含6384和6381节点, 到目前为止, 我们完成了节点的安全下线, 新的集群结构如下图所示。
本节介绍了Redis集群伸缩的原理和操作方式, 它是Redis集群化之后最重要的功能, 熟练掌握集群伸缩技巧后, 以针对线上的数据规模和并发量做到从容应对。

请先 !