简介
本文介绍MySQL的索引的原理。
MySQL的索引默认是使用B+树来实现的。
B+ 树索引并不能找到一个给定键值的具体行。B+ 树索引能找到的只是被查找数据行所在的页。然后数据库通过把页读人到内存,再在内存中进行查找,最后得到要查找的数据。
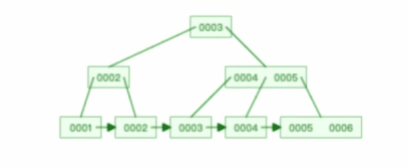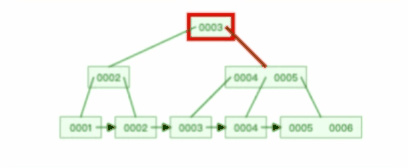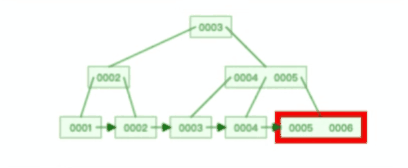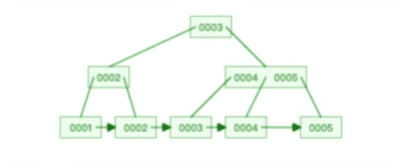
先上一张B+树的图,便于理解下边的内容:
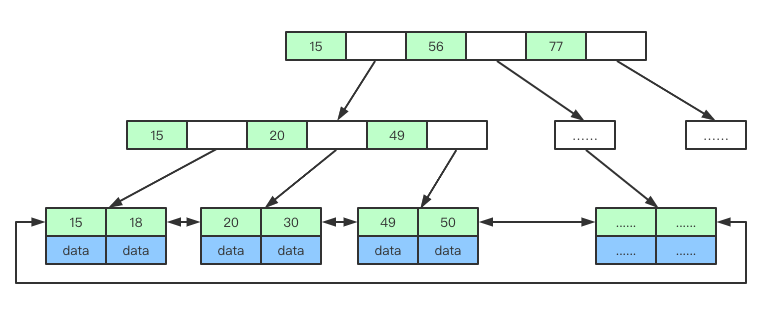
B+ 树的特点(相对于B 树)
- 叶子节点(最底部的节点)才会存放实际数据(索引+记录),非叶子节点只会存放索引;
- 所有索引都会在叶子节点出现,叶子节点之间构成一个有序链表;
- 非叶子节点的索引也会同时存在在子节点中,并且是在子节点中所有索引的最大(或最小)。
- 非叶子节点中有多少个子节点,就有多少个索引;
下面通过三个方面,比较下 B+ 和 B 树的性能区别。
B+ 树对比B树的优点
查询的速度
B+树速度快
B+ 树可以比 B 树更矮胖,查询底层节点的磁盘 I/O次数会更少。因为B+ 树的非叶子节点不存放实际的记录数据,仅存放索引,因此数据量相同的情况下,相比存储即存索引又存记录的 B 树,B+树的非叶子节点可以存放更多的索引。
B树的速度慢
B 树进行单个索引查询时,最快可以在 O(1) 的时间代价内就查到,而从平均时间代价来看,会比 B+ 树稍快一些。
但是 B 树的查询波动会比较大,因为每个节点即存索引又存记录,所以有时候访问到了非叶子节点就可以找到索引,而有时需要访问到叶子节点才能找到索引。
范围查询的速度
B+树速度快
B+ 树所有叶子节点间还有一个链表进行连接,范围查找速度快。比如说我们想知道 12 月 1 日和 12 月 12 日之间的订单,这个时候可以先查找到 12 月 1 日所在的叶子节点,然后利用链表向右遍历,直到找到 12 月12 日的节点,这样就不需要从根节点查询了,节省查询需要的时间。
B树速度慢
B 树没有将所有叶子节点用链表串联起来的结构,因此只能通过树的遍历来完成范围查询,这会涉及多个节点的磁盘 I/O 操作,范围查询效率慢。
插入和删除的速度
B+树插入和删除的速度快
B+ 树有大量的冗余节点,这样使得删除一个节点的时候,可以直接从叶子节点中删除,甚至可以不动非叶子节点,这样删除非常快,比如下面这个动图是删除 B+ 树某个叶子节点节点的过程:
注意:B+ 树对于非叶子节点的子节点和索引的个数,定义方式可能会有不同,有的是说非叶子节点的子节点的个数为 M 阶,而索引的个数为 M-1(这个是维基百科里的定义),因此我本文关于 B+ 树的动图都是基于这个。但是我在前面介绍 B+ 树与 B+ 树的差异时,说的是「非叶子节点中有多少个子节点,就有多少个索引」,主要是 MySQL 用到的 B+ 树就是这个特性。
B+ 树在删除根节点的时候,由于存在冗余的节点,所以不会发生复杂的树的变形,比如下面这个动图是删除 B+ 树根节点的过程:
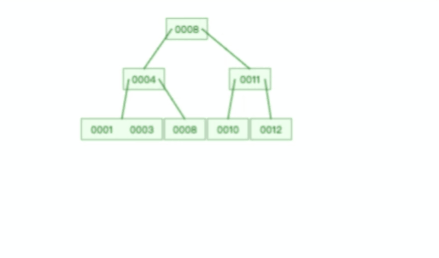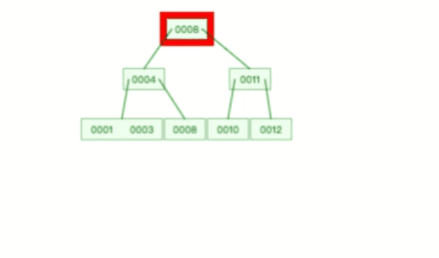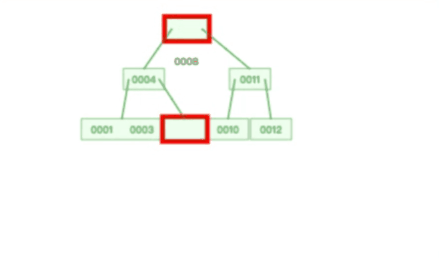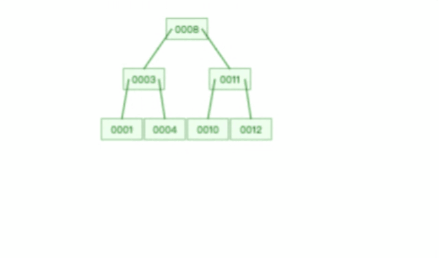
B树插入和删除的速度慢
B 树没有冗余节点,删除节点的时候非常复杂,比如删除根节点中的数据,可能涉及复杂的树的变形,比如下面这个动图是删除 B 树根节点的过程:
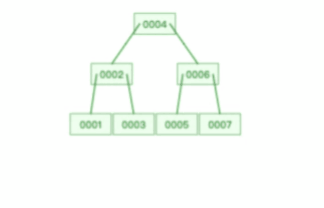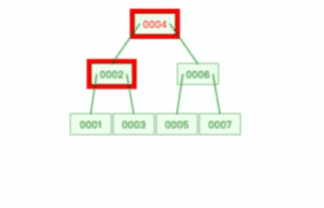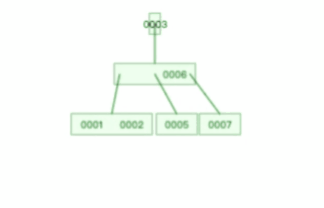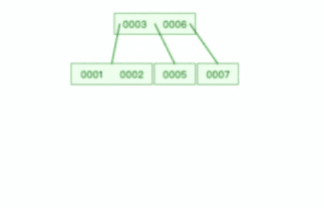
索引合并
mysql文档中对索引合并的说明:
The Index Merge method is used to retrieve rows with several range scans and to merge their results into one. The merge can produce unions, intersections, or unions-of-intersections of its underlying scans. This access method merges index scans from a single table; it does not merge scans across multiple tables.
根据官方文档中的说明,我们可以了解到:
1、索引合并是把几个索引的范围扫描合并成一个索引。
2、索引合并的时候,会对索引进行并集,交集或者先交集再并集操作,以便合并成一个索引。
3、这些需要合并的索引只能是一个表的。不能对多表进行索引合并。
怎么确定使用了索引合并:在使用explain对sql语句进行操作时,如果使用了索引合并,那么在输出内容的type列会显示 index_merge,key列会显示出所有使用的索引。

请先 !