简介
说明
本文介绍MySQL的query cache,buffer pool,key cache的含义与区别。
相关网址
一条SQL查询的总流程
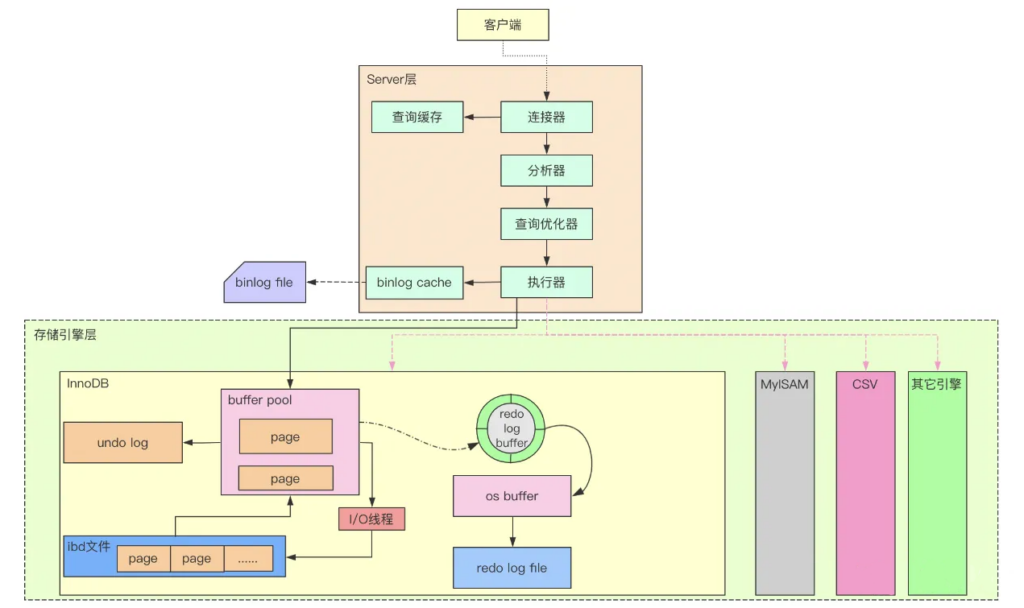
query cache
含义
存在于Server层。查出数据后存到query cache中,后边如果SQL完全相同,则直接从query cache中取。
一般情况下,关闭query cache性能更好。如果线上环境中99%以上都是只读,很少有更新,再考虑开启query cache吧,否则,就别开了
缺点
性能差(缓存命中条件很苛刻,而且很容易失效)。
缓存命中的条件
- SQL的大小写必须完全一样;
- 发起SQL的客户端必须使用同样的字符集和通信协议;
- 同一数据库下的同一个表(不同数据库可能有同名表);
缓存失效的条件
如果表更改(包括表结构和数据的更改),则使用该表的所有query_cache都将变为无效并从query_cache中删除。
不会缓存的情景
- 查询是外部查询的子查询不会缓存;
- 在存储的函数,触发器或事件的主体内执行的查询不会使用缓存;
- SQL查询结果必须确定,即不能带有now()等函数。如果包含,则不会缓存
不同MySQL版本的区别
MySQL5.6:默认关闭query_cache
MySQL5.7.20:废弃query_cache
MySQL8.0:删除query_cache
查看query cache的方法
mysql> show variables like '%query_cache%'; +------------------------------+-------+ | Variable_name | Value | +------------------------------+-------+ | have_query_cache | YES | | query_cache_limit | 0 | | query_cache_min_res_unit | 4096 | | query_cache_size | 0 | | query_cache_type | OFF | | query_cache_wlock_invalidate | OFF | +------------------------------+-------+ 6 rows in set (0.00 sec)
“have_query_cache”:该MySQL是否支持Query Cache;
“query_cache_limit”:Query Cache存放的单条Query最大Result Set,默认1M;
“query_cache_min_res_unit”:Query Cache每个Result Set存放的最小内存大小,默认4k;
“query_cache_size”:系统中用于Query Cache内存的大小;
“query_cache_type”:系统是否打开了Query Cache功能;
“query_cache_wlock_invalidate”:针对于MyISAM存储引擎,设置当有WRITE LOCK在某个Table上面的时候,读请求是要等待WRITE LOCK释放资源之后再查询还是允许直接从Query Cache中读取结果,默认为FALSE(可以直接从Query Cache中取得结果)。
关闭query cache的方法
同时设置如下两项:
- query_cache_type = OFF
- query_cache_size = 0
buffer pool
含义
buffer pool是Innodb存储引擎带的一个缓存池。(默认为128M)。
查询数据的时候,它首先会从buffer pool中查询,如果buffer pool中存在的话,直接返回,从而提高查询响应时间。
修改数据的时候,先在buffer pool中修改,然后达到一定的阈值后,一次性修改到数据库中。
缓冲池LRU算法
当需要空间将新页面添加到缓冲池时,最近最少使用的页面被逐出,并且新页面被添加到列表的中间。此中点插入策略将列表视为两个子列表:
- 在头部是最近访问过的新(“ 年轻 ”)页面的子列表
- 在尾部是最近访问的旧页面的子列表
该算法在新子列表中保留了大量页面。旧子列表包含较少使用的页面; 这些页面是驱逐的候选人 。
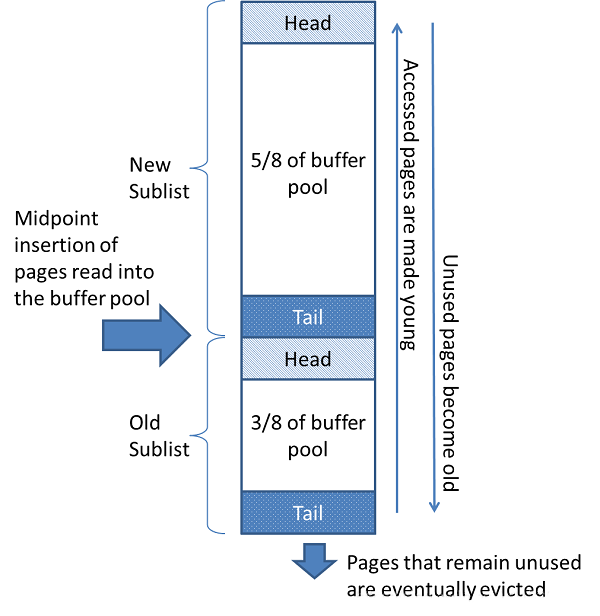
默认情况下,算法操作如下:
- 3/8的缓冲池专用于旧子列表。
- 列表的中点是新子列表的尾部与旧子列表的头部相交的边界。
- 当InnoDB将页面读入缓冲池时,它最初将其插入中点(旧子列表的头部)。可以读取页面,因为它是用户启动的操作(如SQL查询)所必需的,或者是由自动执行的预读操作的一部分 InnoDB。
- 访问旧子列表中的页面使其 “ 年轻 ”,将其移动到新子列表的头部。如果由于用户启动的操作需要读取页面,则第一次访问立即发生,页面变为年轻。如果由于预读操作而读取了页面,则第一次访问不会立即发生,并且可能在页面被驱逐之前根本不会发生。
- 随着数据库的运行,在缓冲池的页面没有被访问的“ 年龄 ”通过向列表的尾部移动。新旧子列表中的页面随着其他页面的变化而变旧。旧子列表中的页面也会随着页面插入中点而老化。最终,仍然未使用的页面到达旧子列表的尾部并被逐出。
默认情况下,查询读取的页面会立即移动到新的子列表中,这意味着它们会更长时间地保留在缓冲池中。例如,为mysqldump操作或SELECT没有WHERE子句的 语句 执行的表扫描可以将大量数据带入缓冲池并逐出相同数量的旧数据,即使新数据从未再次使用过。类似地,由预读后台线程加载并仅访问一次的页面将移动到新列表的头部。这些情况可以将经常使用的页面推送到旧的子列表中,在那里它们会被驱逐。
查询有关缓冲池操作的指标
命令:SHOW ENGINE INNODB STATUS
结果示例
---------------------- BUFFER POOL AND MEMORY ---------------------- Total large memory allocated 2198863872 Dictionary memory allocated 776332 Buffer pool size 131072 Free buffers 124908 Database pages 5720 Old database pages 2071 Modified db pages 910 Pending reads 0 Pending writes: LRU 0, flush list 0, single page 0 Pages made young 4, not young 0 0.10 youngs/s, 0.00 non-youngs/s Pages read 197, created 5523, written 5060 0.00 reads/s, 190.89 creates/s, 244.94 writes/s Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000 Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s LRU len: 5720, unzip_LRU len: 0 I/O sum[0]:cur[0], unzip sum[0]:cur[0]
结果含义
| 名称 | 描述 |
| Total memory allocated | 为缓冲池分配的总内存(以字节为单位)。 |
| Dictionary memory allocated | 为InnoDB数据字典分配的总内存(以字节为单位)。 |
| Buffer pool size | 分配给缓冲池的页面的总大小。 |
| Free buffers | 缓冲池空闲列表的页面总大小。 |
| Database pages | 缓冲池LRU列表的页面总大小。 |
| Old database pages | 缓冲池旧LRU子列表的页面总大小。 |
| Modified db pages | 缓冲池中修改的当前页数。 |
| Pending reads | 等待读入缓冲池的缓冲池页数。 |
| Pending writes LRU | 要从LRU列表底部写入的缓冲池中的旧脏页数。 |
| Pending writes flush list | 在检查点期间要刷新的缓冲池页数。 |
| Pending writes single page | 缓冲池中挂起的独立页面写入次数。 |
| Pages made young | 缓冲池LRU列表中的年轻页总数(移动到“ 新 ”页面的子列表的头部)。 |
| Pages made not young | 缓冲池LRU列表中不再年轻的页面总数(保留在“ 旧 ”子列表中的页面,而不是被当做年轻页面)。 |
| youngs/s | 在缓冲池LRU列表中对旧页面的每秒平均访问次数导致页面变得年轻。 |
| non-youngs/s | 在缓冲池LRU列表中对旧页面的每秒平均访问次数导致不使页面变得年轻。 |
| Pages read | 从缓冲池中读取的总页数。 |
| Pages created | 缓冲池中创建的总页数。 |
| Pages written | 从缓冲池写入的总页数。 |
| reads/s | 每秒缓冲池读取的页面数。 |
| creates/s | 每秒缓冲池创建的页面数。 |
| writes/s | 每秒缓冲池写入的页面数。 |
| Buffer pool hit rate | 从缓冲池内存中读取的页面与从磁盘存储中读取的页面的缓冲池页面命中率。 |
| young-making rate | 页面访问的平均命中率导致页面变得年轻。 |
| not (young-making rate) | 页面访问的平均命中率并未导致页面变得年轻。 |
| Pages read ahead | 每秒预读操作的平均值。 |
| Pages evicted without access | 在没有从缓冲池访问的情况下被逐出的页面的每秒平均值。 |
| Random read ahead | 随机预读操作的每秒平均值。 |
| LRU len | 缓冲池LRU列表的页面总大小。 |
| unzip_LRU len | 缓冲池的总页面大小unzip_LRU列表。 |
| I/O sum | 访问的缓冲池LRU列表页面总数,最近50秒。 |
| I/O cur | 访问的缓冲池LRU列表页面的总数。 |
| I/O unzip sum | 访问的缓冲池unzip_LRU列表页面总数。 |
| I/O unzip cur | 访问的缓冲池unzip_LRU列表页面总数。 |
在理想情况下(保证只有你在操作数据库并且扫描的行数可观),可以在执行查询前后执行SHOW ENGINE INNODB STATUS,关注Buffer pool hit rate和I/O sum的变化(需要注意的是I/O sum保存的是最近50秒的数据)。
- 如果Buffer pool hit rate执行前后保持一致,并且I/O sum执行后增大了,基本上就是获取了buffer pool中的数据了;
- 如果Buffer pool hit rate执行后明显降低了,说明有磁盘读取的数据进来了,这种情况基本上是第一次执行该SQL,或者很久没有执行相关SQL,buffer pool中已经淘汰了这部分数据。
- 但是并不绝对,仅供参考,毕竟这个数据是对整个buffer pool进行分析了,不针对单一SQL。
- 目前没有办法禁用或者直接清除buffer pool,不过可以通过set global innodb_buffer_pool_size=XXX; 把缓冲区的大小调到足够小,并且在验证查询之前先跑一个扫描行数比较可观的查询,把这一部分数据变成新子列表中的数据,这个时候再去执行需要验证的查询,那么很大概率是从磁盘中读取的(不建议在生产环境进行这样的操作,会影响到其它查询性能)。
- 如果是在开发环境进行调优,可以同步生产或者测试环境的数据到本地数据库,通过重启数据库也可以进行buffer pool的清除。
key buffer
含义
key buffer是MyISAM的索引缓存。
MyISAM 索引缓存将 MyISAM 表的索引信息缓存在内存中,以提高其访问性能。
这个缓存可以说是影响 MyISAM 存储引擎性能的最重要因素之一了,通过 key_buffer_size 设置可以使用的最大内存空间。

请先 !