简介
说明
本文介绍ES分词器的使用(知识+实例)。
Elasticsearch之所以全文搜索很快,是因为采用了倒排索引,倒排索引的核心是分词。分词:就是把内容拆分为很多个词语,ES是把text格式的字段按照分词器进行分词并保存为索引的。
本文版本
本文使用的ES版本为:7.15.0 (写本文时的最新稳定版)。
分词详解
Elasticsearch分析器有几个概念:Analysis、Analyzer、Character filters、Tokenizer、Token filter。
Analysis(分析器)功能是把文本切分成词项(词项是倒排索引中的基本单位)。分析器的功能主要是通过分词器(Analyzer)来实现的。
Analyzer由三部分组成:字符过滤器(Character filters)、分词器(Tokenizer)和词元过滤器(Token filter)。每一个Analyzer有且只能有一个tokenizer。
- Character filters:针对原始文本处理,例如去除html
- Tokenizer:按照规则将文本切分为单词
- Token Filter:将切分的单词进行加工,如单词小写、删除stopword、增加同义词等
执行流程如下: 

内置分词器
简介
Elasticsearch已经提供了多种功能强大的内置分词器。
| 分词器 | 作用 |
|---|---|
| Standard | ES默认分词器,把句子分成一个个的单词并转为小写,对于大多数欧洲语言(比如英语)进行分词非常合适。 |
| Simple | 按照非字母字符切分,然后去除非字母字符并转为小写。 |
| Stop | 与简单分词器类似,增加了停用词过滤功能,停用词包括the、a、is。最终按照非字母字符和停用词切分并转为小写。 |
| Whitespace | 按照空格切分。 |
| Language | 对特定语言进行切分。据说提供了30多种常见语言的分词器。 |
| Pattern | 按正则表达式进行分词,支持停用词。默认是\W+,代表非字母。单词会转为小写。 |
| Keyword | 不进行分词,作为一个整体输出。 |
本处的分词器指的是Analyzer,ES也内置了Tokenizer,但常用的是Analyzer这个概念,本处也贴出ES自带的Tokenizer,不是重点,可以跳过。
- Standard Tokenizer
标准分词器将文本划分为单词边界上的术语,这由Unicode文本分段算法定义。它删除大多数标点符号。这是大多数语言的最佳选择。 - Letter Tokenizer
字母分词器在遇到非字母字符时会将文本分为多个术语。 - Lowercase Tokenizer
小写分词器与字母分词器一样,在遇到非字母的字符时,会将文本分为多个词,但所有词都小写。 - Whitespace Tokenizer
每当遇到任何空白字符时,空格tokenizer都会将文本划分为多个term。 - UAX URL Email Tokenizer
uax_url_email tokenizer 类似于standard tokenizer,不同之处在于它将URL和电子邮件地址识别为单个token。 - Classic Tokenizer
经典的分词器是用于英语的基本语法的分词器。 - Thai Tokenizer
泰语分词器将泰语文本分成单词。 - N-Gram Tokenizer
这个tokenizer比较特殊,对于查询不使用空格或长单词的语言(例如德语)很有用。
他会首先按照一定的规则进行分词,然后对每个词输出一个n-gram,就是类似把单词做了一个滑窗处理一样。 - Edge N-Gram Tokenizer
作用类似n-gram,只是返回的分词结果是n-gram的一部分,他要求必须是从token的开头算起的n个char - Keyword Tokenizer
关键字分词器是一个“空”标记器,它接受给出的任何文本,并输出与输入完全相同的文本作为token。它可以与token filter (如lowercase)组合以对分析的术语进行归一化。 - Pattern Tokenizer
模式分词器使用正则表达式在与单词分隔符匹配时将文本拆分为多个token,或将匹配的文本捕获为token。 - Simple Pattern Tokenizer
simple_pattern 分词器使用正则表达式捕获匹配的文本作为term。它使用正则表达式功能的受限子集,并且通常比模式分词器更快。 - Char Group Tokenizer
char_group分词器可通过分割字符集进行配置,通常比运行正则表达式轻量。 - Simple Pattern Split Tokenizer
simple_pattern_split分词器使用与simple_pattern分词器相同的受限正则表达式子集,但是匹配的部分用来拆分输入,而不是将匹配部分作为结果返回。 - Path Tokenizer
路径分词器path_hierarchy分词器采用类似于文件系统路径的分层值,在路径分隔符上拆分,并为树中的每个组件产生一个term,例如/foo/bar/baz -> [/foo,/foo/bar,/foo/bar/baz]。
验证
可以使用ES的_analyze来查看如何分词的。
查看默认分词器的分词情况
POST _analyze
{
"text": "我们是软件工程师"
}
结果(每个字都被拆开,且没有词语组合):
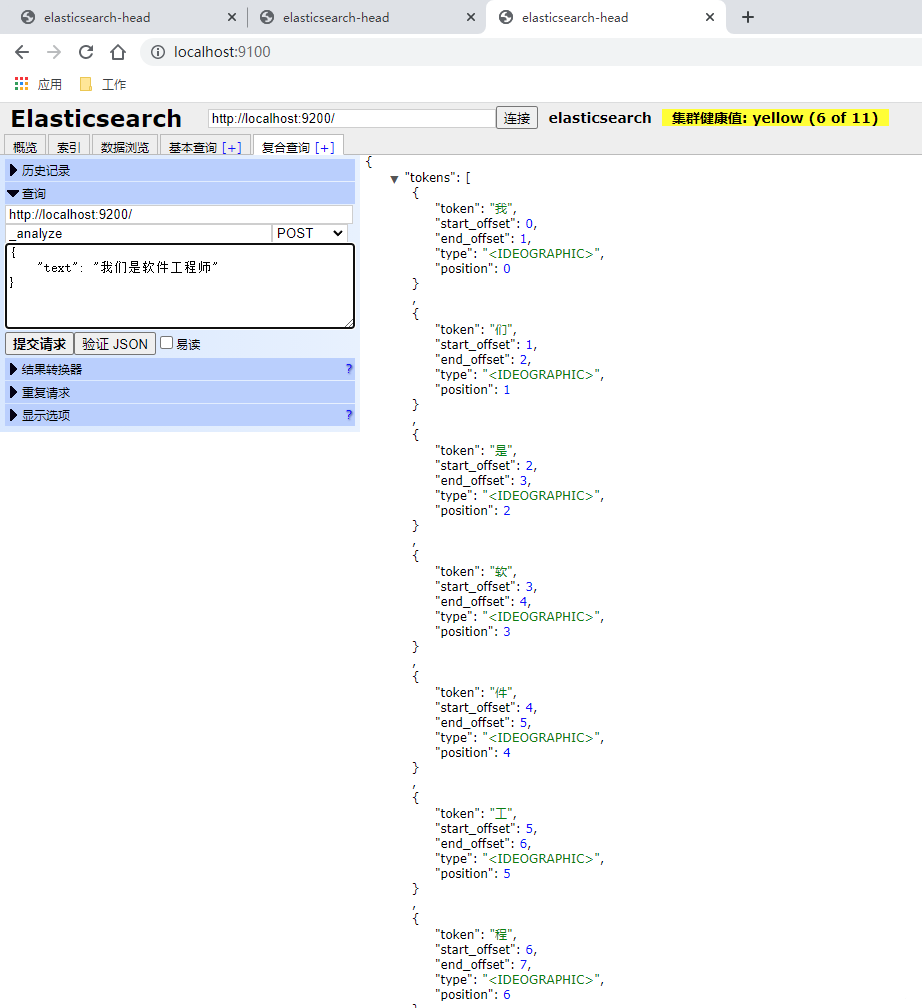
贴出全部结果
{
"tokens": [{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
}, {
"token": "们",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
}, {
"token": "是",
"start_offset": 2,
"end_offset": 3,
"type": "<IDEOGRAPHIC>",
"position": 2
}, {
"token": "软",
"start_offset": 3,
"end_offset": 4,
"type": "<IDEOGRAPHIC>",
"position": 3
}, {
"token": "件",
"start_offset": 4,
"end_offset": 5,
"type": "<IDEOGRAPHIC>",
"position": 4
}, {
"token": "工",
"start_offset": 5,
"end_offset": 6,
"type": "<IDEOGRAPHIC>",
"position": 5
}, {
"token": "程",
"start_offset": 6,
"end_offset": 7,
"type": "<IDEOGRAPHIC>",
"position": 6
}, {
"token": "师",
"start_offset": 7,
"end_offset": 8,
"type": "<IDEOGRAPHIC>",
"position": 7
}
]
}
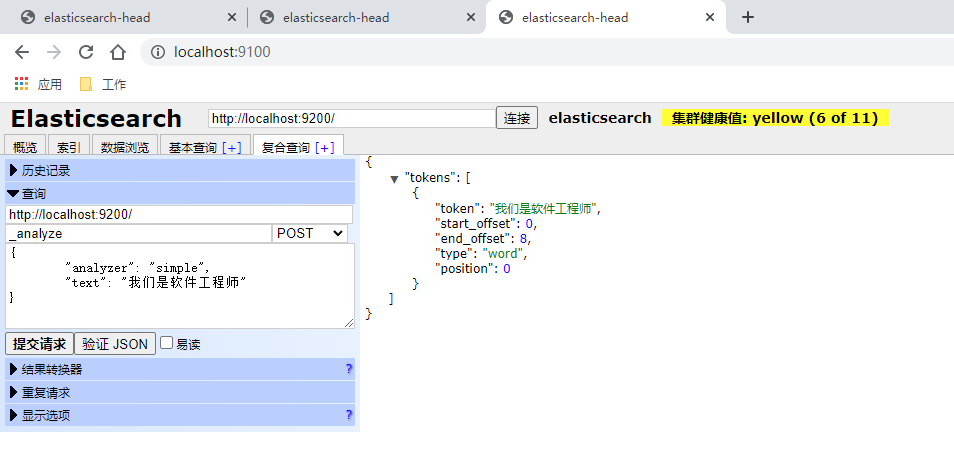
查看指定分词器的分词情况
本处以simple为例
POST _analyze
{
"analyzer": "simple",
"text": "我们是软件工程师"
}
结果:(没有分)
中文分词器
简介
说明
从上边“内置分词器”的“实例”中可以看到,对汉字没有很好的分词。比如:软件、工程、工程师,这三个应该单独作为分词的。
考虑如下场景:我想搜索“软件”这两个字,但文档1里边有“微软的文件”这几个字,它也会被搜出,这是不合理的。
常用的中文分词器
- IK
- 支持自定义词库,支持热更新分词字典
- ICU Analyzer
- 提供了Unicode的支持,更好的支持亚洲语言
- THULAC
推荐使用IK分词器,这也是目前使用最多的分词器。本文使用IK分词器进行实例验证。
ik分词器介绍
ik分词器有两种Analyzer也有两种Tokenizer:
Analyzer: ik_smart , ik_max_word;Tokenizer: ik_smart , ik_max_word
安装ik分词器
1.下载
https://github.com/medcl/elasticsearch-analysis-ik

本处我在windows下验证,所以下载:elasticsearch-analysis-ik-7.15.0.zip
2.安装
在ES的安装目录的plugins目录下新建ik目录,将上边文件解压后放进去,结果:
实例
测试1:ik_smart
POST _analyze
{
"analyzer": "ik_smart",
"text": "我们是软件工程师"
}
结果

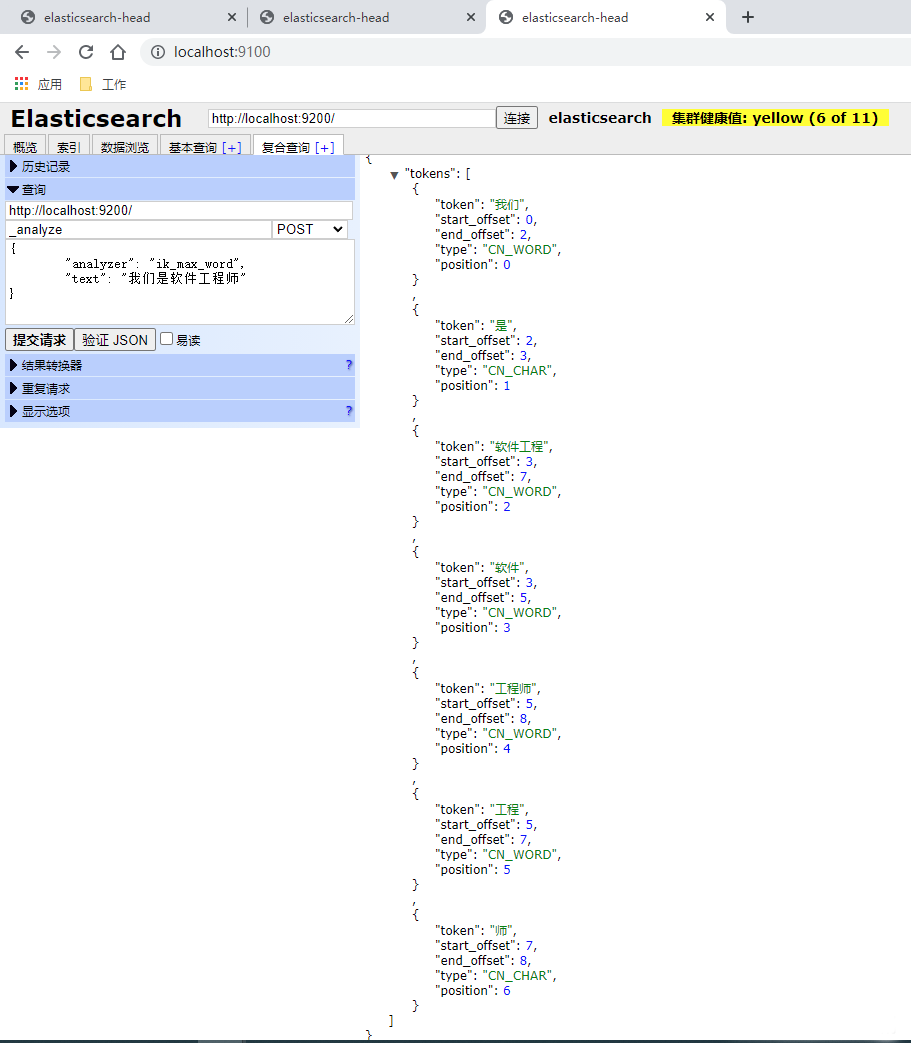
测试2:ik_max_word
POST _analyze
{
"analyzer": "ik_max_word",
"text": "我们是软件工程师"
}
结果
analyzer和search_analyzer
说明
分析器(analyzer)主要有两种情况会被使用:
- 插入文档时,将text类型的字段做分词然后插入倒排索引,。
- 在查询时,先对要查询的text类型的输入做分词,再去倒排索引搜索。
在索引(即插入文档)时,只会去看字段有没有定义analyzer,有定义的话就用定义的,没定义就用ES预设的。
在查询时,会先去看字段有没有定义search_analyzer,如果没有定义,就去看有没有analyzer,再没有定义,才会去使用ES预设的。
默认情况下,插入文档和查询使用的是同一种分析器,即字段映射中设置的analyzer,例如:
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_smart"
}
}
}
}
我们也可以在插入文档和查询使用不同的分析器:(下边这种配置也是项目中常用的)
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_smart",
"search-analyzer": "ik_max_word"
}
}
}
}
官网

请先 !