简介
说明
本文介绍HTTP的报文结构。
官网
请求报文结构
简介
post

get
情况1:无请求体
GET /demo/user/?name=Tony&password=1234 HTTP/1.1 Host: oa.funds.com.cn:9080 Connection: Keep-Alive User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/7.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E) Accept: */* Accept-Language: zh-CN Accept-Encoding: gzip, deflate Cookie: JSESSIONID=0000AgK4N-vgetNoKBOfYd_hJQP 空行
情况2:有请求体

get和post区别
另见:《JSP&Servlet学习笔记》
| 比较方面 | get | post |
| 作用 | 获得服务器指定的资源 | 发布信息给服务器 |
| 参数位置 | 请求行或者请求体 (参数长度无限制,若参数在请求行会出现在地址栏) | 请求体 (参数长度无限制、不会出现在地址栏) |
| 浏览器回退 | 不会重新提交请求 | 会重新提交请求 |
| 是否等幂操作 | 是等幂操作 | 不一定是等幂操作 |
GET和POST的区别和应用?
这问题挺复杂。简而言之,就是“安全”和“不安全”的区别。什么是安全?不用承担责任。什么是不安全?可能需要承担责任。举个例子,点击某个链接以同意某个协议,这个请求明显就是不安全的,因为需要承担责任。如果采用GET,就违反了GET应该用于安全请求的规范。因为浏览器可能在你不知情的情况下预加载这个页面(因为是“安全”的GET请求),这样相当于你在不知情的情况下同意了某个协议,这显然是我们不希望看到的。在契约式的设计里,违反契约的行为是会带来严重的后果的。浏览器按照契约预加载了安全的GET请求,但这本身是不安全的,带来的后果自然要由打破契约的人承担(将这个请求设计成GET的人出来挨打)。
之所以强调“安全”,而不是按照常规的说法强调副作用,因为有副作用的请求不代表不安全;举例来说,服务器有一个显示访问人数的功能,这个功能就可以用GET来做。虽然每次访问都会发送改变服务器状态(计数器)的请求,但用户不会因为这个请求承担责任,这个请求是安全的。至于什么GET请求的URL有长度限制(后来事实证明其实没有),什么GET请求的URL里不能有中文(或者说非ASCII吧),都只是实现上的区别;从最初的设计上来说区别并不在这里。
当然,这些都是纯粹的理论层面的东西。如果遵守RESTful的规范,采用语义化的GET/POST请求,自然也就不会有这些问题了。因为通常来说,查询是安全的;这也是GET的主要作用。
请求行
第一行GET http://www.kkh86.com/http-test.do HTTP/1.1就叫做请求行,这行内容又分为以下三个元素:
请求方法
第一个词表示了本次HTTP请求的方法(GET、POST、PUT、DELETE、HEAD、OPTIONS、TRACE、CONNECT)
请求地址
通常是一个 URL,或者是协议、端口和域名的绝对路径,通常以请求的环境为特征。请求的格式因不同的 HTTP 方法而异。它可以是:
- 一个绝对路径,末尾跟上一个 ‘ ? ‘ 和查询字符串。这是最常见的形式,称为 原始形式 (origin form),被 GET,POST,HEAD 和 OPTIONS 方法所使用。此时浏览器会自动根据当前网页的域名(host头)拼接成完整的地址构成HTTP请求信息
- POST / HTTP/1.1
- GET /background.png HTTP/1.0
- HEAD /test.html?query=alibaba HTTP/1.1
- OPTIONS /anypage.html HTTP/1.0
- 一个完整的URL,被称为 绝对形式 (absolute form),主要在使用 GET 方法连接到代理时使用。
- GET http://developer.mozilla.org/en-US/docs/Web/HTTP/Messages HTTP/1.1
- 由域名和可选端口(以’:’为前缀)组成的 URL 的 authority component,称为 authority form。 仅在使用 CONNECT 建立 HTTP 隧道时才使用。
- CONNECT developer.mozilla.org:80 HTTP/1.1
- 星号形式 (asterisk form),一个简单的星号(‘*’),配合 OPTIONS 方法使用,代表整个服务器。
- OPTIONS * HTTP/1.1
在非浏览器的请求场景中,比如通过PHP的curl函数发起请求,又或是Java、C#等代码,都必须写入完整网址,不然你只写相对路径的话人家怎么知道往哪个host发送请求呢
协议版本
HTTP1.1表示本次通讯数据格式的书写排版是遵循HTTP的1.1版本协议的,HTTP最初的版本是1.0,但没多久就升级为1.1了,至少目前我还没见过哪个软件还使用1.0版本协议来通讯。
我虽然看过几次1.1和1.0的具体区别,但其实多年来发现知道这些区别对我们日常开发来说没任何作用,而最后我也背不出来,建议你不要去关心这些版本区别吧,因为我可以说的就是当今能在我们各种系统中使用的浏览器都使用1.1版本与服务器通讯,你学了1.0的东西也不知往哪用。
这个版本可以说是万年不变的,1.0因为某些缺陷被废弃了,1.1正在流行,无论你用什么抓包、浏览器抓包都是看到这个版本号,会看腻的。
在未来5~10年等HTTP2.0版本普及后就能在抓包过程中发现1.1和2.0两个版本号了
请求头
其他网址
简介
可以追加自定义请求头 。
Request Context
Host
- 示例:Host: https://www.baidu.com/
- 指定服务器的地址和端口号(端口号若不指定默认为80)
Referer
- 示例:Referer:https://www.baidu.com/xxxxxxxxxx
- 作用:告诉服务器该页面从哪个页面链接的
- 解释:该页面从 https://www.baidu.com 中的搜索结果中点击过来的
Content Negotiation
Accept
- 示例:Accept:text/html, application/xhtml+xml, application/xml;q=0.9, image/webp, image/apng, */*; q=0.8
- 作用:向服务器申明客户端(浏览器)可以接受的媒体类型(MIME)的资源
- 解释:浏览器可以接受 text/html、application/xhtml+xml、application/xml类型,通配符*/* 表示任意类型的数据。并且浏览器按照该顺序进行接收。( text/html —> application/xhtml+xml —> application/xml)
Accept-encoding
- 示例:Accept-encoding: gzip, deflate, br
- 作用:向服务器申明客户端(浏览器)接收的编码方法,通常为压缩方法
- 解释:浏览器支持采用经过 gzip,deflate 或 br 压缩过的资源
Accept-Language
- 示例:Accept-Language: en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7
- 作用:向服务器申明客户端(浏览器)接收的语言
- 解释:浏览器能够接受 en-US, en 和 zh-CN 三种语言,其中 en-US 的权重最高 ( q 最高为1,最低为 0),服务器优先返回 en-US 语言
- 延伸:语言与字符集的区别:zh-CN 为汉语,汉语中有许多的编码:gbk2312 等
Caching
Cache-control
- 示例:Cache-control: max-age=0
- 作用:控制浏览器的缓存,常见值为 private、no-cache、max-age、alidate,默认为 private,根据浏览器查看页面不同的方式来进行区别
- 解释:浏览器在访问了该页面后,不再会访问服务器
Cookies
Cookie
- 作用:告诉服务器关于 Session 的信息,存储让服务器辨识用户身份的信息。
Upgrade-insecure-requests
- 示例:Upgrade-insecure-requests:1
- 作用:申明浏览器支持从 http 请求自动升级为 https 请求,并且在以后发送请求的时候都使用 https
- 解释:当页面中包含大量的 http 资源的时候(图片、iframe),如果服务器发现一旦存在上述的响应头的时候,会在加载 http 资源的时候自动替换为 https 请求
User-agent
- 示例:User-agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36
- 作用:向服务器发送浏览器的版本、系统、应用程序的信息。
- 解释:Chrome 浏览器的版本信息为 63.0.3239.132,并将自己伪装成 Safari,使用的是 WebKit 引擎,WebKit伪装成 KHTML,KHTML伪装成Gecko(伪装是为了接收那些为Mozilla、safari、gecko编写的界面)
- 延伸:可以随便填(但不应该随便填)不过一般用于统计。
X-Chrome-UMA-Enabled、X-Client-Data :与 Chrome 浏览器相关的数据
请求体
get是否包含body?
http规范:对get和post都没有body限制和URI长度限制(即可以一样用);但规定了get用于获取资源,post用于添加。
html规范:规定了get不能带有body。如果请求不是用html发送,当然可以包含body。
GET 请求能包含 body 但最好不要这么做。标准没有禁止,但也没有定义语义。老版本的postman是不支持在GET请求里加body的,新版本的postman则支持,如下图所示(版本为v7.27.1)
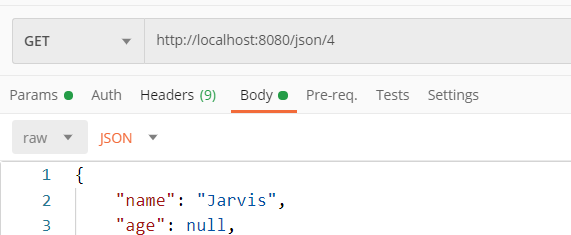
不建议get带body的原因
- 就算服务器不会忽略 GET 请求的body,各种代理和缓存可能也会过滤body。
- GET 被设计来用 URI 来识别资源,若请求体中带数据,那么通常的缓存服务便失效了,URI 不能作为缓存的 Key。
正常操作
如果在浏览器里用form标签加submit按钮提交的话,浏览器会自动将参数组装成UrlEncode格式,包括在jquery里如果这样传入一个key value对象也会自动转换成UrlEncode,最后会变成name=Jay&age=11放到请求体里面 :
$.post('/xx.do', {
name : 'Jay',
age : 11
});
$.ajax({
url : '/xx.do',
data : {
name : 'Jay',
age : 11
}
});
自定义请求体
要自定义格式的话只能通过ajax请求来发送:
$.ajax({
url : '/xx.do',
data : JSON.stringify({
name : 'Jay',
age : 11
})
});
这样构造的请求报文大概如下(主要是最后一行,请求体不是UrlEncode而是JSON):
POST http://kk/xx.do HTTP/1.1
Host: kk
Connection: keep-alive
Content-Length: 23
Pragma: no-cache
Cache-Control: no-cache
Origin: http://kk
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.3368.400 QQBrowser/9.6.11974.400
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Accept: */*
Referer: http://kk/it/index.html
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.8
{"name":"Jay","age":11}
响应头
Accpet-ranges:bytes
- 作用:表明自己是否接收获取某个实体的一部分(比如文件的一部分)
- 解释:接受
- 延伸:服务器支持断点续传,以及同时下载文件的多个部分时,必须设置为 bytes
Alt-svc: hq=”:443”; ma=2592000; quic=51303431; quic=51303339; quic=51303338; quic=51303337; quic=51303335,quic=”:443”; ma=2592000; v=”41,39,38,37,35”
- 作用:服务器使用“alt-svc”(Alternative Servicesde)标识资源,可以通过不同的网络位置或者网络协议进行获取
Content-length:24211
- 作用:HTTP消息实体的传输长度
- 解释:该实体的传输长度(被 br 压缩后的长度为)24211
Content-encoding:br
- 作用:设置数据使用的编码类型(压缩类型)
- 解释:数据使用 br 进行压缩后返回到浏览器上
Content-type:text/html; charset=UTF-8
- 作用:设置响应体的媒体资源类型(MIME)
- 解释:服务器发送 html 文档,字符集为 UTF-8
Age:1037016
- 作用:表明该响应从缓存中拿到时响应的寿命,代理服务器当前的系统时间与此应答消息中的通用消息头Date的值之差
- 解释:该响应在缓存代理中存放了 1037016 秒
Date:Thu, 15 Feb 2018 20:31:45 GMT
- 作用:设置响应被服务器创建的时间
- 解释:在 GMT(格林威治标准时间)Thu, 15 Feb 2018 20:31:45,发送的响应
Expires:Fri, 01 Feb 2019 17:33:57 GMT
- 作用:设置响应体的过期时间。如果在过期之前进行访问,就会读取缓存中的版本。
- 解释:在 GMT(格林威治标准时间)Fri, 01 Feb 2019 17:33:57,在这个时间之前,客户端不用再向服务器发送请求
- 延伸:如果和 Cache-control 同时存在,那么被其中的 max-age 覆盖
Last-modified:Mon, 12 Dec 2016 14:45:00 GMT
- 作用:设置该文件在服务器端中最后被修改的时间
- 解释:在 GMT(格林威治标准时间)Fri, 01 Feb 2019 17:33:57,该文件被服务器所修改
Vary:Accept-Encoding
- 作用:服务器响应时根据请求头中的的值返回不同的内容的
- 过程:浏览器 —> 请求 —> squid —> 请求 —> apache
- 解释:
- apache 在 response headers 中 返回了 vary: Accept-Encoding,
- 在 squid 中需要存储该 encoding 的值作为缓存 key 的值,比如,resourse_1 : gzip, resourse_2: deflate
- 下次请求到 squid,需要先找到缓存文件的索引文件,根据不同的 accept-Encoding(gzip、deflate)的值来找相应的文件。
p3p:CP=”This is not a P3P policy! See g.co/p3phelp for more info.”
- 作用:隐私安全平台(the Platform for Privary Preferences),网站向浏览器申明自己的隐私政策。
Server: gws
- 作用:设置服务器名称
Set-cookie:
- 作用:设置 http 的 Cookie
Status: 200
- 作用:设置HTTP的响应状态
- 解释:200 代表成功请求
Strict-transport-security: max-age=3600
- 作用:HSTS 策略,告诉 HTTP 客户端缓存 HTTPS 策略多少时间。
- 解释:在 3600 秒内,不管用户在浏览器输入不带协议的网址如:google.com 时,还是http协议的网址如:http://google.com ,都会默认将请求内部跳转到 https://google.com
X-frame-options: SAMEORIGIN
- 作用:点击劫持保护
- 解释:页面可以在相同域名页面的 frame中展示
X-content-type-options: nosniff
- 作用:设置浏览器的”MIME”攻击机制
- 解释:服务器中的内容是 image/png,那么浏览器就会显示为 image/png
X-xss-protection:1; mode=block
- 作用:设置浏览器的XSS防护机制
- 解释:浏览器如果检测到恶意代码,则不渲染恶意代码

请先 !