简介
本文介绍分布式的CAP定理。
CAP定理概述
说明
一个分布式系统不可能同时满足一致性(C:Consistency)、可用性(A:Availability)和分区容错性(P:Partition tolerance)这三个基本需求,最多只能同时满足其中的两项。
- 一致性(Consistency)
- 每次访问都能获得最新数据,但可能会收到错误响应。
- 可用性(Availability)
- 每次访问都能收到成功的响应(响应时间也正常),但不保证获取到最新数据。
- “Reads and writes always succeed”
- 分区容错性(Partition tolerance)
- 在网络分区的情况下,即使出现单个节点无法可用,系统依然正常对外提供服务。
如何选择
在分布式系统中,在任何数据库设计中,一个Web应用至多只能同时支持上面的两个属性。显然,任何横向扩展策略都要依赖于数据分区。因此,设计人员必须在一致性与可用性之间做出选择。
对于一个业务系统来说,可用性和分区容错性是必须要满足的两个条件,并且这两者是相辅相成的。业务系统之所以使用分布式系统,主要原因有两个:
- 提升整体性能 :当业务量猛增,单个服务器已经无法满足我们的业务需求的时候,就需要使用分布式系统,使用多个节点提供相同的功能,从而整体上提升系统的性能,这就是使用分布式系统的第一个原因。
- 实现分区容错性 :单一节点 或 多个节点处于相同的网络环境下,那么会存在一定的风险,万一该机房断电、该地区发生自然灾害,那么业务系统就全面瘫痪了。为了防止这一问题,采用分布式系统,将多个子系统分布在不同的地域、不同的机房中,从而保证系统高可用性。
这说明分区容错性是分布式系统的根本,如果分区容错性不能满足,那使用分布式系统将失去意义。
CAP定理详述
Consistency(一致性)
概念
一致性指“all nodes see the same data at the same time”,即所有节点在同一时间的数据完全一致。
一致性是因为多个数据拷贝下并发读写才有的问题,因此理解时一定要注意结合考虑多个数据拷贝下并发读写的场景。
对于一致性,可以分为从客户端和服务端两个不同的视角。
- 客户端
- 从客户端来看,一致性指的是并发访问时更新过的数据如何获取的问题。
- 服务端
- 从服务端来看,则是更新如何分布到整个系统,以保证数据最终一致。
数据一致性的基础理论
从客户端角度,多进程并发访问时,更新过的数据在不同进程如何获取的不同策略,决定了不同的一致性。对于一致性,可以分为强/弱/最终一致性 三类
- 强一致
- 当更新操作完成之后,任何多个后续进程或者线程的访问都会返回最新的更新过的值。
- 弱一致性
- 系统并不保证续进程或者线程的访问都会返回最新的更新过的值。系统在数据写入成功之后,不承诺立即可以读到最新写入的值,也不会具体的承诺多久之后可以读到。
- 最终一致性
- 弱一致性的特定形式。
- 经过一段时间后要求能访问到更新后的数据。
- 在没有故障发生的前提下,不一致窗口的时间主要受通信延迟,系统负载和复制副本的个数影响。DNS 是一个典型的最终一致性系统。
Availability(可用性)
可用性指“Reads and writes always succeed”,即:每次访问都能收到成功的响应(响应时间也正常),但不保证获取到最新数据。
好的可用性主要是指系统能够很好的为用户服务,不出现用户操作失败或者访问超时等用户体验不好的情况。通常情况下可用性和分布式数据冗余,负载均衡等有着很大的关联。
Partition Tolerance(分区容错性)
分区容错性指“the system continues to operate despite arbitrary message loss or failure of part of the system”,即:分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性或可用性的服务。
CAP为什么只能取两个?
CAP的基本场景
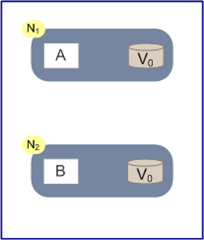
上图网络中有两个节点:N1和N2,可以理解为N1和N2是两台计算机,它们网络连通,N1中有一个应用程序A和一个数据库V;N2也有一个应用程序B和一个数据库V。
现在,A和B是分布式系统的两个部分,V是分布式系统的数据存储的两个子数据库。
CAP情景如下:
- 在满足一致性的时候,N1和N2中的数据是一样的,V0=V0。
- 在满足可用性的时候,用户不管是请求N1或者N2,都会立即得到响应。
- 在满足分区容错性的时候,N1和N2有任何一方宕机,或者网络不通的时候,都不会影响N1和N2彼此之间的正常运作。
分布式系统正常运转的流程
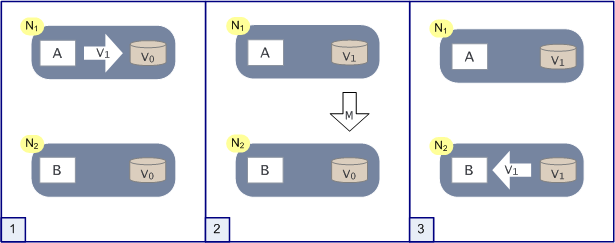
上图是分布式系统正常运转的流程,用户向N1机器请求数据更新,程序A更新数据库V0为V1,分布式系统将数据进行同步(M),将N2中的V0同步为V1,后边V1会作为对N2请求的响应。
出现异常
假设N1和N2之间的网络断开,我们要支持这种网络异常,相当于要满足分区容错性,能不能同时满足一致性和可用性呢?
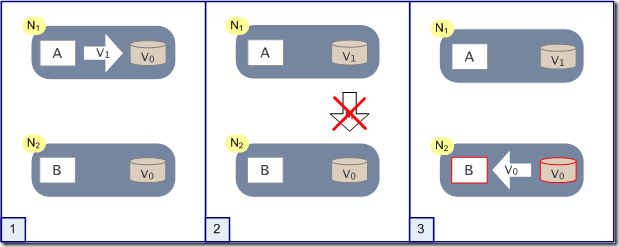
假设在N1和N2之间网络断开的时候,有用户向N1发送数据更新请求,那N1中的数据V0将被更新为V1,由于网络是断开的,所以分布式系统同步操作M无法进行,N2中的数据依旧是V0;这个时候,有用户向N2发送数据读取请求,由于数据还没有进行同步,应用程序没办法立即给用户返回最新的数据V1,怎么办呢?
有两种选择:
- 牺牲数据一致性,响应旧的数据V0给用户;
- 牺牲可用性,阻塞等待,直到网络连接恢复,数据更新操作M完成之后,再给用户响应最新的数据V1。
这个过程,证明了要满足分区容错性的分布式系统,只能在一致性和可用性两者中,选择其中一个。
CAP的实际使用
服务的CAP
示例1:Redis
Redis集群(主备+集群)是AP:一个主备里,一个节点下线,其他节点可以提供服务。
注册中心的CAP
示例:Nacos
官网地址:
Nacos同时支持AP/CP两种模式。(外部不可选,是Nacos内部同时有这两种协议运行着)
Nacos对服务注册的管理
官网:Nacos中持久化服务和临时服务的区别 | Nacos 官网
临时服务(ephemeral=true) 使用AP模式
微服务应用停止或与Nacos服务器的连接断开,Nacos会自动移除这些服务实例的注册信息。这适用于应用程序(频繁启停、动态IP变化的环境)。客户端上报心跳进行服务实例续约。
服务之间感知对方服务的当前可正常提供服务的实例信息是从服务发现注册中心进行获取,需要保证可用性(尽最大可能保证服务注册发现能力可以对外提供服务)。同时 Nacos 的服务注册发现设计,采取了心跳可自动完成服务数据补偿的机制,如果数据丢失的话,会通过该机制快速弥补数据丢失。
持久化服务(ephemeral=false) 使用CP模式
持久化服务的注册信息不会因微服务实例的正常上下线而自动删除,用户需主动发起请求删除服务。这类服务由Nacos服务端进行健康检查。适合于MySQL服务、DNS服务等需要长期稳定注册、易于审计维护的场景。
持久化服务所有的数据都是Nacos服务端直接创建,因此需要由Nacos保障数据在各个节点之间的强一致性,故而针对此类型的服务数据,选择了强一致性共识算法来保障数据的一致性。
Nacos对配置的管理(CP模式)
配置数据,是直接在 Nacos 服务端进行创建并管理的,必须保证大部分的节点都保存了此配置数据才能认为配置被成功保存了,否则就会丢失配置的变更,如果丢失,问题是很严重的。
因此对于配置数据的管理,要求集群中大部分的节点是强一致的。
注册中心支持的项
| 框架 | CAP |
| Eureka | AP |
| Nacos | AP/CP |
| Zookeeper | CP |
| Consul | CP |

请先 !