简介
本文介绍Kafka是如何能够支撑高并发的。也就是:Kafka为什么吞吐量大、速度快。
Kafka是分布式消息系统,一般用于处理海量的消息。Kafka高性能、高吞吐量、低延时。
Kafka的设计是把所有的消息都写入速度低容量大的硬盘,以此来换取更强大的存储能力,但实际上,使用硬盘并没有带来过多的性能损失。相反,Kafka性能高、速度快。
kafka主要使用了以下几种方式实现了超高的吞吐量:
- 数据压缩
- 批量传输
- 并行
- Page Cache
- 零拷贝
- 顺序读写硬盘
1.数据压缩
简介
Producer 可将数据压缩后发送给 broker,从而减少网络传输代价。
详解
- Kafka使用了批量压缩,即将多个消息一起压缩而不是单个消息压缩。(如果每个消息都压缩,压缩率相对较低。)
- Kafka允许使用递归的消息集合,批量的消息可通过压缩的形式传输并且在日志中也可保持压缩格式,直到被消费者解压缩
- Kafka支持多种压缩协议,包括Gzip、Snappy、LZ4
2.批量传输
简介
在向Kafka发送数据时,可以启用批次发送,这样可以避免在网络上频繁传输单个消息带来的延迟和带宽开销。假设网络带宽为10MB/S,一次性传输10MB的消息比传输1KB的消息10000万次显然要快得多。
详解
kafka允许进行批量发送消息,先将消息缓存在内存中,然后一次请求批量发送出去,然后将这批数据flush到磁盘(partition的segement)文件。比如可以指定缓存的消息达到某一个量的时候就发出去,或者缓存了固定的时间后就发送出去。比如:达到100条消息就发送,或者每5秒发送一次,这种策略将大大减少服务端的I/O次数。
(Message)消息flush到磁盘上,flush策略,以下两个参数在server.properties文件中
log.flush.interval.messages= log.flush.interval.ms=
3.并行
概述
- 由于不同 Partition 可位于不同机器,因此可以充分利用集群优势,实现机器间的并行处理。
- 由于 Partition 在物理上对应一个文件夹,即使多个 Partition 位于同一个节点,也可通过配置让同一节点上的不同 Partition 置于不同的磁盘上,从而实现磁盘间的并行处理,充分发挥多磁盘的优势。
详解
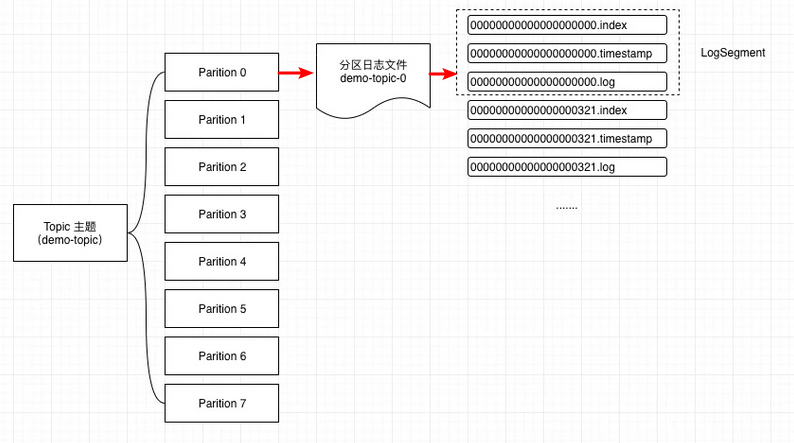
Kafka的message是按topic分类存储的,topic中的数据又是按照一个一个的partition即分区存储到不同broker节点。每个partition对应了操作系统上的一个文件夹,partition实际上又是按照segment分段存储的。这也非常符合分布式系统分区分桶的设计思想。
通过这种分区分段的设计,Kafka的message消息实际上是分布式存储在一个一个小的segment中的,每次文件操作也是直接操作的segment。为了进一步的查询优化,Kafka又默认为分段后的数据文件建立了索引文件,就是文件系统上的.index文件。这种分区分段+索引的设计,不仅提升了数据读取的效率,同时也提高了数据操作的并行度。
4.Page Cache
简介
为了优化读写性能,Kafka利用了操作系统本身的Page Cache,就是利用操作系统自身的内存而不是JVM空间内存。这样做的好处有:
- 避免Object消耗:如果是使用 Java 堆,Java对象的内存消耗比较大,通常是所存储数据的两倍甚至更多。
- 避免GC问题:随着JVM中数据不断增多,垃圾回收将会变得复杂与缓慢,使用系统缓存就不会存在GC问题
详解
使用 Page Cache 的好处:
- I/O Scheduler 会将连续的小块写组装成大块的物理写从而提高性能
- I/O Scheduler 会尝试将一些写操作重新按顺序排好,从而减少磁盘头的移动时间
- 充分利用所有空闲内存(非 JVM 内存)。如果使用应用层 Cache(即 JVM 堆内存),会增加 GC 负担
- 读操作可直接在 Page Cache 内进行。如果消费和生产速度相当,甚至不需要通过物理磁盘(直接通过 Page Cache)交换数据
- 如果进程重启,JVM 内的 Cache 会失效,但 Page Cache 仍然可用
Broker 收到数据后,写磁盘时只是将数据写入 Page Cache,并不保证数据一定完全写入磁盘。从这一点看,可能会造成机器宕机时,Page Cache 内的数据未写入磁盘从而造成数据丢失。但是这种丢失只发生在机器断电等造成操作系统不工作的场景,而这种场景完全可以由 Kafka 层面的 Replication 机制去解决。如果为了保证这种情况下数据不丢失而强制将 Page Cache 中的数据 Flush 到磁盘,反而会降低性能。也正因如此,Kafka 虽然提供了 flush.messages 和 flush.ms 两个参数将 Page Cache 中的数据强制 Flush 到磁盘,但是 Kafka 并不建议使用。
5.零拷贝
简介
Kafka 的生产和消费两个过程都使用了零拷贝(zero copy):
- 网络数据持久化到磁盘 (Producer 到 Broker)。(使用了mmap)
- 磁盘文件通过网络发送(Broker 到 Consumer)。(使用了DMA)
零拷贝
零拷贝(Zero-copy)技术指在计算机执行操作时,CPU 不需要先将数据从一个内存区域复制到另一个内存区域,从而可以减少上下文切换以及 CPU 的拷贝时间。它的作用是减少数据拷贝次数,减少系统调用,实现 CPU 的零参与,彻底消除 CPU 在这方面的负载。
目前零拷贝技术主要有三种类型:
- 直接I/O:数据直接跨过内核,在用户地址空间与I/O设备之间传递,内核只是进行必要的虚拟存储配置等辅助工作;
- 避免内核和用户空间之间的数据拷贝:当应用程序不需要对数据进行访问时,则可以避免将数据从内核空间拷贝到用户空间
- mmap
- sendfile
- splice && tee
- sockmap
- copy on write:写时拷贝技术,数据不需要提前拷贝,而是当需要修改的时候再进行部分拷贝。
网络数据持久化到磁盘 (Producer 到 Broker)
传统的数据传输
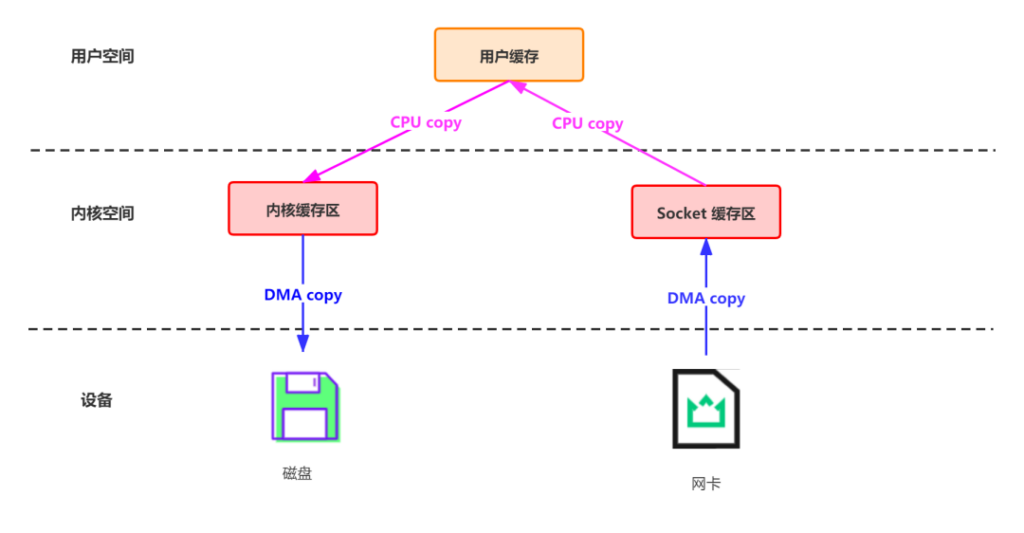
这一过程实际上发生了四次数据拷贝(还伴随着四次上下文切换):
- 首先通过 DMA copy 将网络数据拷贝到内核态 Socket Buffer
- 然后应用程序将内核态 Buffer 数据读入用户态(CPU copy)
- 接着用户程序将用户态 Buffer 再拷贝到内核态(CPU copy)
- 最后通过 DMA copy 将数据拷贝到磁盘文件
Kafka利用mmap进行传输
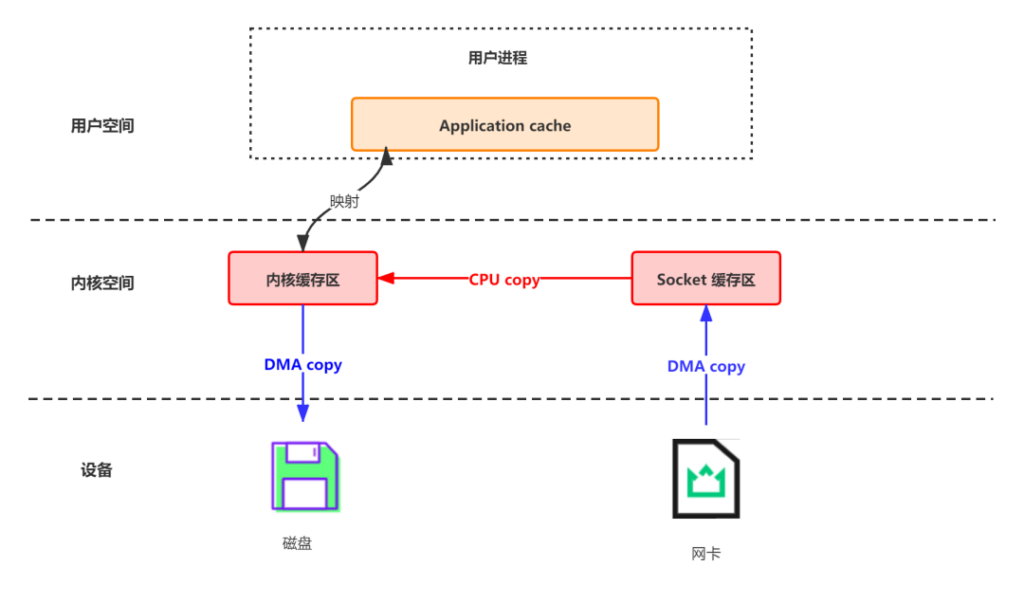
Memory Mapped Files:简称 mmap,将内核中读缓冲区(read buffer)的地址与用户空间的缓冲区(user buffer)进行映射。从而实现内核缓冲区与应用程序内存的共享,省去了将数据从内核读缓冲区(read buffer)拷贝到用户缓冲区(user buffer)的过程。它的工作原理是直接利用操作系统的 Page 来实现文件到物理内存的直接映射。完成映射之后你对物理内存的操作会被同步到硬盘上。
使用这种方式可以获取很大的 I/O 提升,省去了用户空间到内核空间复制的开销。
mmap 也有一个很明显的缺陷:不可靠,写到 mmap 中的数据并没有被真正的写到硬盘,操作系统会在程序主动调用 flush 的时候才把数据真正的写到硬盘。Kafka 提供了一个参数——producer.type 来控制是不是主动flush;如果 Kafka 写入到 mmap 之后就立即 flush 然后再返回 Producer 叫同步(sync);写入 mmap 之后立即返回 Producer 不调用 flush 就叫异步(async),默认是 sync。
磁盘文件通过网络发送(Broker 到 Consumer)
传统的数据传输
传统方式实现:先读取磁盘、再用 socket 发送,实际也是进过四次 copy。
这一过程可以类比上边的生产消息:
- 首先通过系统调用将文件数据读入到内核态 Buffer(DMA 拷贝)
- 然后应用程序将内存态 Buffer 数据读入到用户态 Buffer(CPU 拷贝)
- 接着用户程序通过 Socket 发送数据时将用户态 Buffer 数据拷贝到内核态 Buffer(CPU 拷贝)
- 最后通过 DMA 拷贝将数据拷贝到 NIC Buffer
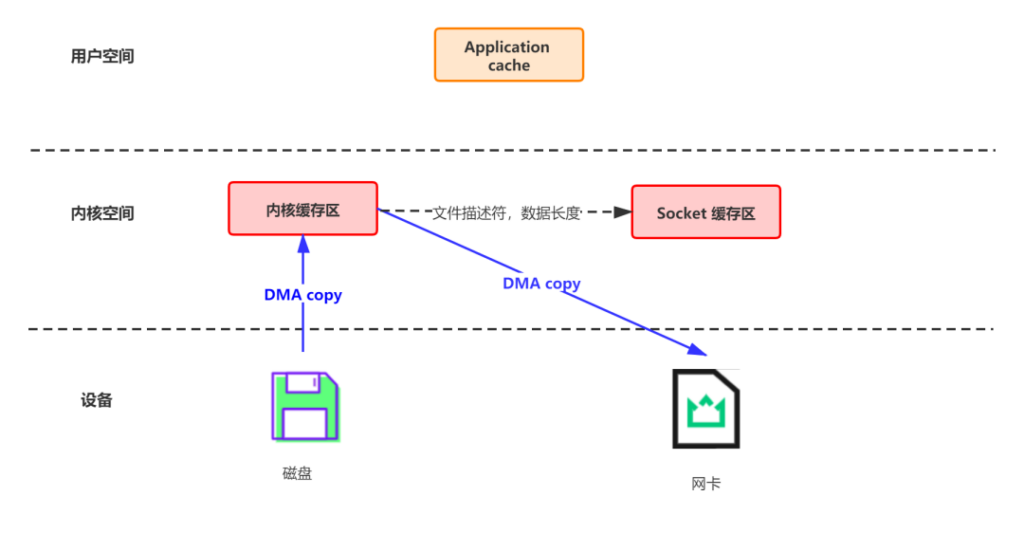
Kafka利用sendFile进行传输
总共发生 2 次内核数据拷贝、2 次上下文切换和一次系统调用,消除了 CPU 数据拷贝
Linux 2.4+ 内核通过 sendfile 系统调用,提供了零拷贝。数据通过 DMA 拷贝到内核态 Buffer 后,直接通过 DMA 拷贝到 NIC Buffer,无需 CPU 拷贝。这也是零拷贝这一说法的来源。除了减少数据拷贝外,因为整个读文件 – 网络发送由一个 sendfile 调用完成,整个过程只有两次上下文切换,因此大大提高了性能。
6.顺序读写硬盘
简介
Kafka将消息记录到本地磁盘中,采用的是顺序读写的方式(message是不断追加到本地磁盘文件末尾的,而不是随机的写入)。
磁盘的随机读写很慢,但磁盘的顺序读写性能却很高,一般而言要高出磁盘随机读写三个数量级。
如下图所示,kafka官方给出了测试数据 (Raid-5,7200rpm):顺序 I/O:600MB/S;随机 I/O: 100KB/S。链接:Apache Kafka

详解
顺序写:Kafka 中每个分区是一个有序的,不可变的消息序列,新的消息不断追加到 partition 的末尾,这个就是顺序写。
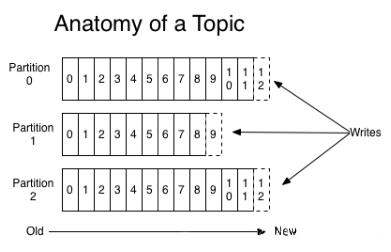
顺序读:每个消费者(Consumer)对每个Topic都有一个offset用来表示下一次读取第几条数据 :
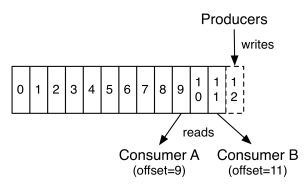
如上图所示:假设两个消费者ConsumerA和B都从一个Topic的一个Partition读数据,ConsumerA和B都有一个offset,这个offset是由客户端SDK负责保存的,Kafka的Broker完全无视这个东西的存在;一般情况下SDK会把它保存到zookeeper里面。(所以需要给Consumer提供zookeeper的地址)。
删除数据
由于磁盘有限,不可能保存所有数据,实际上作为消息系统 Kafka 也没必要保存所有数据,需要删除旧的数据。又由于顺序写入的原因,所以 Kafka 采用各种删除策略删除数据的时候,并非通过使用“读 – 写”模式去修改文件,而是将 Partition 分为多个 Segment,每个 Segment 对应一个物理文件,通过删除整个文件的方式去删除 Partition 内的数据。这种方式清除旧数据的方式,也避免了对文件的随机写操作。
Kakfa提供了两种策略来删除数据。一是基于时间,二是基于partition文件大小。

请先 !