简介
说明
本文介绍Java中HashMap的原理,包括:数据结构、存取机制、hashCode方法。
HashMap原理总结
HashMap其实就是数组,将key的hashCode对数组长度取余作为数组的下标,将value作为数组的值。如果key的hashCode重复(即:数组的下标重复),则将新的key和旧的key放到链表中。
若链表长度大于8 且容量小于64 会进行扩容;若链表长度大于8 且数组长度大于等于64,会转化为红黑树(提高定位元素的速度);若红黑树节点个数小于等于6,则将红黑树转为链表。
数据结构
数组和链表
数据结构中有数组和链表来实现对数据的存储,但这两者各有利弊。
| 项 | 数组 | 链表 |
| 内存连续性 | 存储地址连续。 | 存储地址不连续。 |
| 查找的速度 | 快。(时间复杂度小,为O(1)) | 慢。(时间复杂度很大,为O(N)) |
| 插入和删除的速度 | 慢。 | 快。 |
哈希表
哈希表:综合数组和链表的特性:查找(寻址)容易,插入删除容易、占空间中等的数据结构。
哈希表有多种不同的实现方法,HashMap则使用的是拉链法,也叫作【链地址法】。
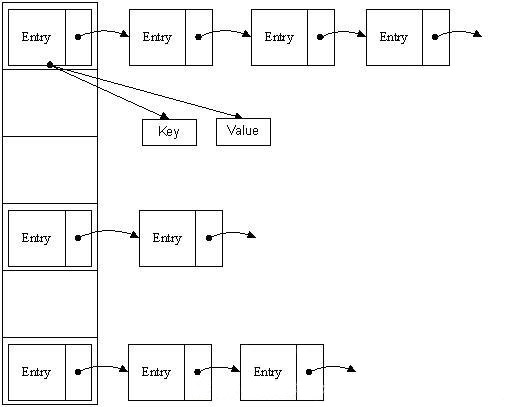
示例
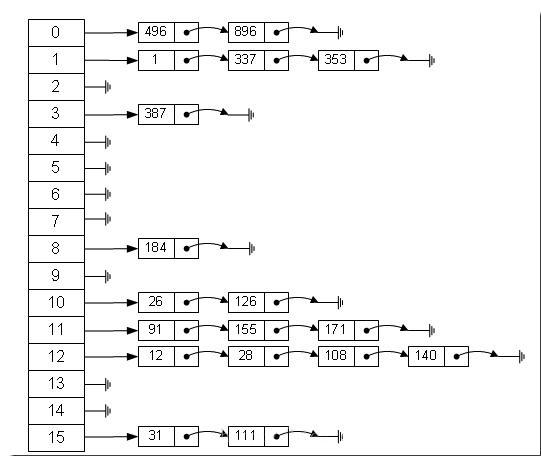
哈希表的数组的初始长度为16,每个元素存储的是一个链表的头结点。这些元素是按照什么样的规则存储到数组中呢?一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表中:
12%16=12;28%16=12;108%16=12;140%16=12
所以:12、28、108、140都存储在数组下标为12的位置。
红黑树
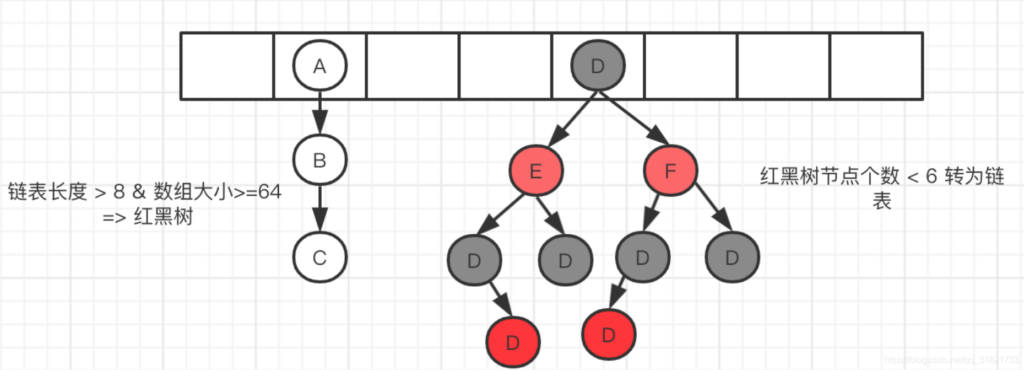
存取机制
键值对的数据
每个键值对都是一个Node<K,V>对象,它实现了Map.Entry<K,V>接口。Node<K,V>有四个属性:hash、key、value、next(下一个节点)。
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
}
// 其他代码
}
既然是线性数组,为什么能随机存取?这里HashMap用了一个小算法,大致是这样实现:
// 存储时: int hash = key.hashCode(); int index = hash % Entry[].length; Entry[index] = value; // 取值时: int hash = key.hashCode(); int index = hash % Entry[].length; return Entry[index];
put
哈希冲突
若两个key通过hash%Entry[].length得到的index相同,怎么处理?HashMap用的链表(链地址法)。Entry类里面有一个next属性,指向下一个Entry。(JDK7是头插法;JDK8是尾插法)
get
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
//先定位到数组元素,再遍历该元素处的链表
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
null key的存取
null key总是存放在Entry[]数组的第一个元素。
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
private V getForNullKey() {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
确定数组
index:hashcode % table.length取模
HashMap存取时,都需要计算当前key应该对应Entry[]数组哪个元素,即计算数组下标;算法如下:
// Returns index for hash code h.
static int indexFor(int h, int length) {
return h & (length-1);
}
按位取并,作用上相当于取模mod或者取余%;这意味着数组下标相同,并不表示hashCode相同。
table初始大小
public HashMap(int initialCapacity, float loadFactor) {
.....
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];
init();
}
注意table初始大小并不是构造函数中的initialCapacity!!
而是 >= initialCapacity的2的n次幂!
hashCode方法
源码(String#hashCode)
String#hashCode
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
为什么乘31呢?
选31是因为它是一个奇素(质)数,这里有两层意思:奇数 && 素数。
1.为什么是奇数,偶数不行?
因为如果乘子是个偶数,并且当乘法溢出的时候(数太大,int装不下),相当于在做移位运算,有信息就损失了。
比如说只给2bit空间,二进制的10,乘以2相当于左移1位,10(bin)<<1=00,1就损失了。
2.为什么是素数?
作者说:你问我我问谁,这是传统吧。素数比较流弊。
那么,问题又来了,那么多个奇素数,为什么就看上了31呢。
3.为什么偏偏是31?
h*31 == (h<<5)-h; 现代虚拟机会自动做这样的优化,算得快。
再反观这种“选美标准”下的其它数,
h*7 == (h<<3)-h; // 太小了,容易hash冲突
h*15 == (h<<4)-h; // 15不是素数
h*31 == (h<<5)-h; // 31既是素数又不大不小刚刚好
h*63 == (h<<6)-h; // 63不是素数
h*127 == (h<<7)-h; // 太大了,乘不到几下就溢出了
实例追踪
“abc”.hashCode()
hash为:0
value为:[a, b, c]
第一次循环:h = 0 + 97 = 97
第二次循环:h = 31 * 97 + 98 = 3105
第三次循环:h = 3105 * 31 + 99 = 96354


请先 !