简介
本文LRU算法的原理、Java实现、应用。
LRU算法全称是:Least Recently Used,即:检查最近最少使用的数据。这个算法通常使用在内存淘汰策略中,用于将不常用的数据转移出内存,将空间腾给最近更常用的“热点数据”。
LRU算法的原理
一般来讲,LRU将访问数据的顺序或时间和数据本身维护在一个容器当中。当访问一个数据时:
- 若该数据不在容器中,则设置该数据的优先级为最高并放入容器中。
- 若该数据在容器当中,则更新该数据的优先级至最高。
当数据的总量达到上限后,则移除容器中优先级最低的数据。下图是一个简单的LRU原理示意图:
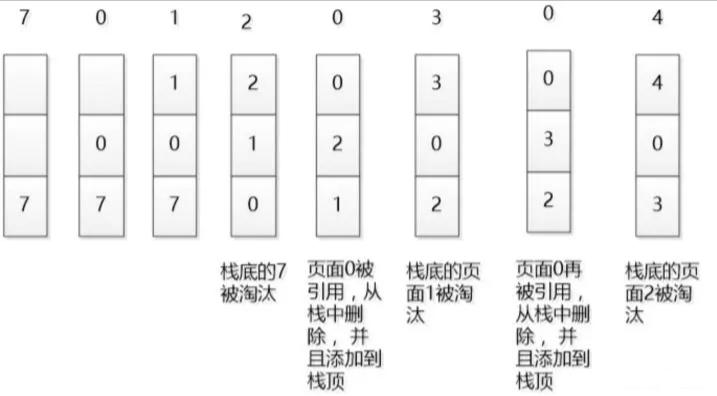
如果我们按照7 0 1 2 0 3 0 4的顺序来访问数据,且数据的总量上限为3,则如上图所示,LRU算法会依次淘汰7 1 2这三个数据。
Java实现
实现方案
LRU算法实现要支持的项:
- 在任意位置删除、在末尾进行添加。
- 按照访问(使用)顺序排序。
- 数据量超过一定阈值后,需要删除Least Recently Used数据。
各个实现方法的对比如下:
基于数组
方案:为每一个数据附加一个额外的属性——时间戳,当每一次访问数据时,更新该数据的时间戳至当前时间。当数据空间已满后,则扫描整个数组,淘汰时间戳最小的数据。
不足:维护时间戳需要额外的空间,淘汰数据时需要扫描整个数组(时间复杂度为O(n),效率低)
基于长度有限的双向链表
方案:访问一个数据时,当数据不在链表中,则将数据插入至链表头部,如果在链表中,则将该数据移至链表头部。当数据空间已满后,则淘汰链表最末尾的数据。
不足:插入数据或取数据时,需要扫描整个链表(时间复杂度为O(n),效率低)。
基于双向链表和哈希表
方案:为了改进上面需要扫描链表的缺陷,配合哈希表,将数据和链表中的节点形成映射,将插入操作和读取操作的时间复杂度从O(N)降至O(1)。
java.util.LinkedHashMap已经实现了其中的99%,因此直接基于LinkedHashMap实现LRUCache非常简单。
基于Java的LinkedHashMap实现示例
- LinkedHashMap底层就是用的HashMap加双链表实现的
- LinkedHashMap支持按照访问顺序的存储。
- LinkedHashMap实现了一个方法removeEldestEntry用于判断是否需要移除最不常读取的数,方法默认是直接返回false,不会移除元素。需要重写该方法:即当缓存满后就移除最不常用的数。
// 继承LinkedHashMap
public class LRUCache<K, V> extends LinkedHashMap<K, V> {
private final int MAX_CACHE_SIZE;
public LRUCache(int cacheSize) {
// 第三个参数要设置为true,按访问排序
super((int) Math.ceil(cacheSize / 0.75) + 1, 0.75f, true);
MAX_CACHE_SIZE = cacheSize;
}
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
// 超过阈值时返回true,进行LRU淘汰
return size() > MAX_CACHE_SIZE;
}
}
LRU的应用
MySQL的Buffer Pool
LRU 在 MySQL 的应用就是 Buffer Pool,也就是缓冲池。
缓冲池的目的是为了减少磁盘 IO,它是一块连续的内存,默认大小 128M,可以进行修改。这一块连续的内存,被划分为若干默认大小为 16KB 的页。
既然它是一个 pool,那么必然有满了的时候,这时候就要移除某些页了,为了减少磁盘 IO,所以应该淘汰掉很久没有被访问过的页,这个就是 LRU 。
Redis
Redis会有满的时候,满了就要淘汰掉长期不使用的key,在 Redis 中用了一个类似的 LRU 算法,而不是严格的 LRU 算法。
Dubbo
Dubbo的LRU缓存LRUCache使用LinkedHashMap实现了LRU算法。
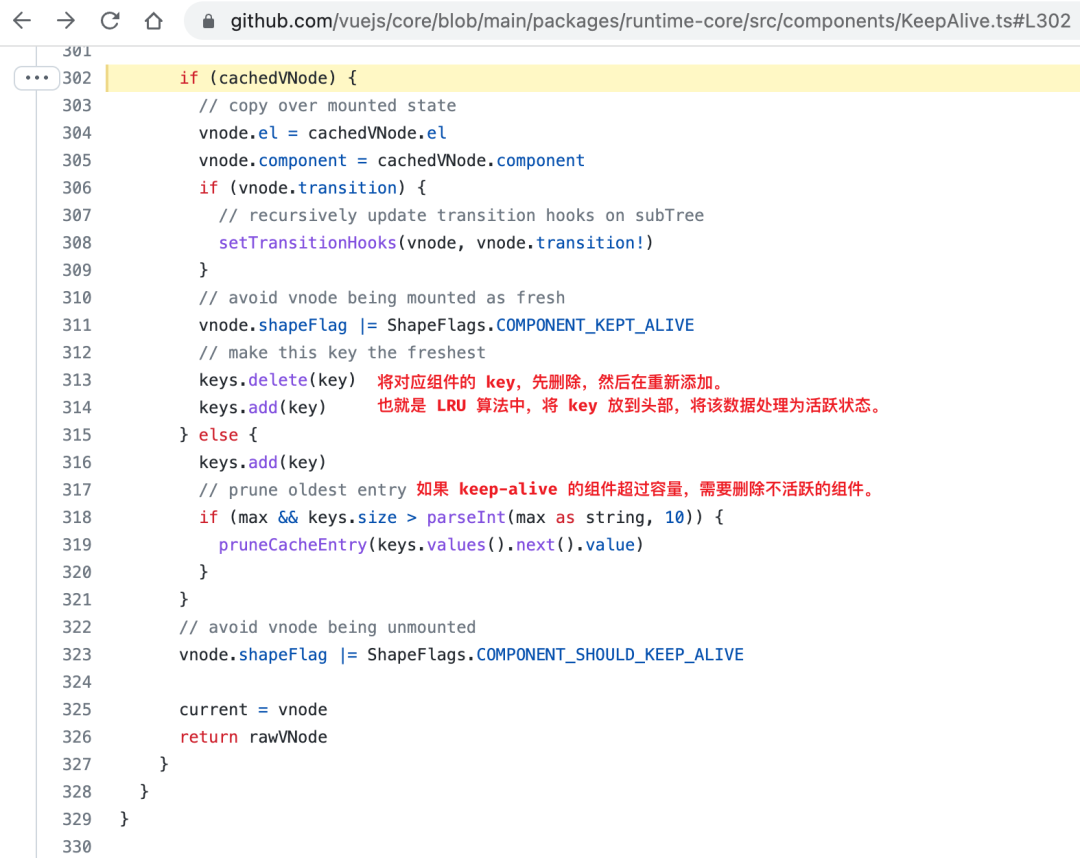
Vue 的内置组件 keep-alive
Vue 的内置组件 keep-alive 使用了 LRU 算法。

请先 !