简介
说明
本文介绍如何修复ES的非健康状态(黄色或者红色)。
相关网址
ES–排查集群健康状态是Red、Yellow的问题 – 自学精灵
分片变得未分配的原因有很多种。下文概述了最常见的原因及其解决方案。
1. 重新启用分片分配
节点重启过或者设置过禁用分片分配,但之后忘记设置重新分配策略,Elasticsearch 将无法分配分片。
需要手动更新集群设置才可以实现重新分配。
PUT _cluster/settings
{
"persistent" : {
"cluster.routing.allocation.enable" : null
}
}
2. 调整节点下线时分片分配策略
当数据节点下线或特定原因宕机导致离开集群时,分片通常会变成未分配状态。造成这种情况的原因很多,比如:连接问题;比如:硬件故障问题等。
当这些故障解决后,下线节点重新加入集群,然后Elasaticsearch 将自动分配之前因节点下线等原因导致的未分配的分片。
为了避免在上述问题上浪费资源,Elasticsearch 默认将分配延迟一分钟。根据业务实际需要,比如:因升级内存而下线数据节点的场景,可以将该延时值调大。
参考命令行:
PUT _all/_settings
{
"settings": {
"index.unassigned.node_left.delayed_timeout": "5m"
}
}
如果已恢复节点并且不想等待延迟期,则可以调用不带参数的集群 reroute API 来启动分配过程。该进程在后台异步运行。
POST _cluster/reroute
3. 减少副本数量
为了防止硬件故障,Elasticsearch 不会将副本分配给与其主分片相同的节点。
如果只有一个ES节点,没有其他数据节点可用于分配副本分片,则该副本分片保持未分配状态。要解决此问题,你可以:
- 添加相同角色的数据节点。
- 通过更新 index.number_of_replicas 索引设置减少每个主分片的副本数。
如下是集群层面的设置,将副本数设置为0,设置后对整个集群生效。
PUT _settings
{
"index.number_of_replicas": 0
}
结果
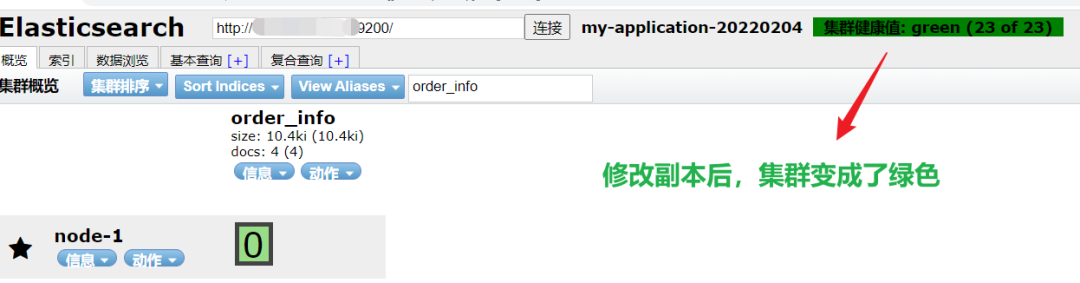
PS:为保证集群的高可用性,建议每个主节点至少保留一个副本。
4. 释放或增加磁盘空间
Elasticsearch 使用 low disk watermark(低磁盘警戒水平线)来确保数据节点有足够的磁盘空间来接收分片。
默认情况下,Elasticsearch 不会将分片分配给磁盘使用率超过 85% 的节点。要检查节点的当前磁盘空间,请使用 cat allocation API。
GET _cat/allocation?v=true&h=node,shards,disk.*
结果

如果你的节点磁盘空间不足,你通常有如下四个细化方案:
- 方案 1:升级节点以增加磁盘空间。
- 方案 2:删除不需要的索引以释放空间。
- 如果你使用 ILM 索引生命周期管理,可以更新生命周期策略以使用可搜索快照或添加删除阶段。
- 如果你不再需要搜索数据,可以使用快照将其历史数据存储在集群外。
- PS:这里强调的删除索引,delete操作,不是删除数据的 delete_by_query 操作,切记!
- 方案 3:如果你不再写入索引,请使用强制合并 API( force merge API ) 或 ILM 的强制合并操作将其段合并为更大的段。
POST order_info/_forcemerge
结果

- 方案 4:如果索引是只读的,请使用 shrink index API 或 ILM 的 shrink action 来减少其主分片数。
PUT order_index_ext
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 0
}
}
POST order_index_ext/_bulk
{"index":{"_id":1}}
{"title":"just testing..."}
{"index":{"_id":2}}
{"title":"just testing..."}
{"index":{"_id":3}}
{"title":"just testing..."}
PUT order_index_ext/_settings
{
"index.blocks.write":"true"
}
POST order_index_ext/_shrink/order_shrink_index
结果
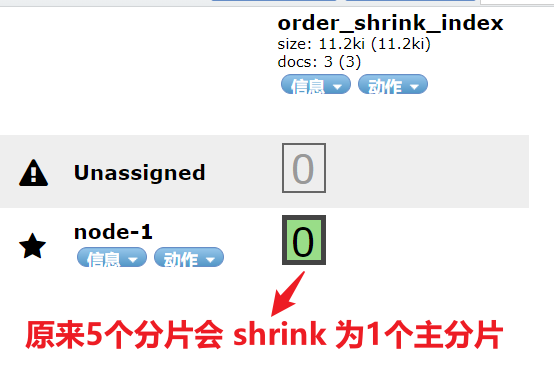
- 方案 5:如果你的节点具有较大的磁盘容量,你可以调大低磁盘警戒水位线的值或将其设置为显式字节值。
具体设置,参考如下:
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.disk.watermark.low": "30gb"
}
}
5. 减少 JVM 堆内存压力
分片分配需要 JVM 堆内存。高 JVM 内存压力可能会触发停止分片分配并使分片未分配的断路器(出现内存熔断现象)。
6. 修正分片分配的设置
分片分配设置错误可能会导致主分片无法分配。这些设置包括但不限于:
- 索引层面的分片分配设置;
- 集群层面的分片分配设置;
- 集群层面的感知(awareness)分片分配设置。
为了获取分片分配的细节设置,推荐使用如下两个 API:
GET order_info/_settings?flat_settings=true&include_defaults=true GET _cluster/settings?flat_settings=true&include_defaults=true
结果:
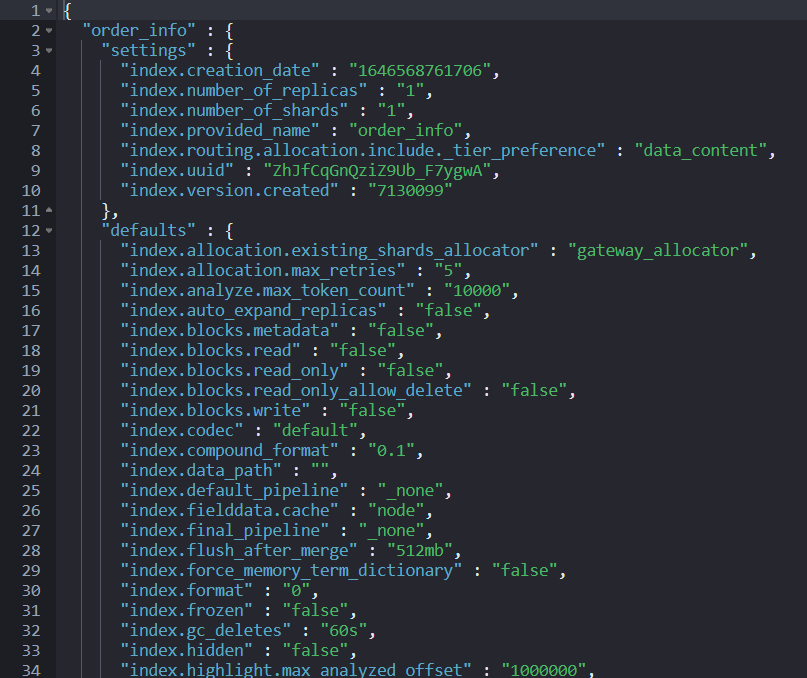
注意:
- flat_settings 标志会影响设置列表的呈现。当 flat_settings 标志为 true 时,相关设置以平面格式返回,如上图所示。
- include_defaults 默认值是 false,如果为 true,则代表返回集群所有缺省值。
更多参数设置,见:
Common options | Elasticsearch Guide [8.3] | Elastic
Cluster get settings API | Elasticsearch Guide [8.3] | Elastic
7. 主分片丢失情况的恢复策略
如果包含主分片的节点因故障或其他原因下线,Elasticsearch 通常可以使用另一个节点上的副本替换它。
如果包含主分片的节点无法恢复或其副本不存在或无法恢复(这是比较极端的情况),则需要从快照或原始数据源重新添加丢失的数据。
注意
仅当节点不再可能成功恢复时才使用此选项。因为:此过程分配一个空的主分片。如果节点稍后重新加入集群,Elasticsearch 将用这个较新的空分片中的数据覆盖其主分片,从而导致数据丢失。
使用集群重新路由 reroute API 手动将未分配的主分片分配给同一角色中的另一个数据节点。将参数 accept_data_loss 设置为 true。
POST _cluster/reroute
{
"commands": [
{
"allocate_empty_primary": {
"index": "order_info",
"shard": 0,
"node": "node-1",
"accept_data_loss": "true"
}
}
]
}

请先 !