简介
本文介绍SpringCloud的ribbon的负载均衡的原理。
我另外一篇文章的最后分析到了负载均衡:Feign最终调用Ribbon进行负载均衡。
负载均衡概述
负载均衡在系统架构中非常重要,一定要去实施,因为负载均衡是对系统的高可用、网络压力的缓解和处理能力扩容的重要手段之一。我们通常所说的负载均衡都指的是服务端负载均衡,其中分为硬件负载均衡和软件负载均衡。硬件负载均衡主要通过在服务器节点之间安装专门用于负载均衡的设备,比如F5 等;而软件负载均衡则是通过在服务器上安装一些具有均衡负载功能或模块的软件来完成请求分发工作,比如Nginx等。
在 Spring Cloud 构建的微服务系统中, Ribbon 作为服务消费者的负载均衡器,有两种使用
方式,一种是和 RestTemplate 相结合,另一种是和 Feign 相结合(Feign 已经默认集成了 Ribbon)。
Ribbon与 Eureka整合后,Ribbon会从Eureka Server中获取服务实例清单,将其放到本应用里存放,当调用其他服务时会根据这个服务实例清单的信息进行负载均衡,选择要调用的服务。
Ribbon 有很多子模块,但很多模块没有用于生产环境,目前 Netflix 公司用于生产环境的Ribbon子模块如下:
- ribbon-loadbalancer:可以独立使用或与其他模块一起使用的负载均衡器 API。
- ribbon-eureka: Ribbon 结合 Eureka 客户端的 API,为负载均衡器提供动态服务注册列表信息。
- ribbon-core: Ribbon 的核心 API。
负载均衡器
SpringCloud中定义了LoadBalancerClient作为负载均衡器的通用接口,并且针对Ribbon实现了RibbonLoadBalancerClient,但它在具体实现客户端负载均衡时,是通过Ribbon的ILoadBalancer接口实现的。下面我们根据ILoadBalancer接口的实现类逐个看看它是如何实现客户端负载均衡的。
AbstractLoadBalancer
AbstractLoadBalancer是ILoadBalancer接口的抽象实现。
源码:
public abstract class AbstractLoadBalancer implements ILoadBalancer {
public enum ServerGroup{
ALL,
STATUSJJP,
STATUS_NOT_UP
}
public Server chooseServer{) {
return chooseServer(null);
}
public abstract List<Server> getServerList(ServerGroup serverGroup);
public abstract LoadBalancerStats getLoadBalancerStats();
}
在该抽象类中定义了一个关于服务实例的分组枚举类ServerGroup,它包含以下三种不同类型。
- ALL:所有服务实例。
- STATUS_UP:正常服务的实例。
- STATUS_N〇T_UP:停止服务的实例。
另外,还实现了一个chooseServer()函数,该函数通过调用接口中的chooseServer(Objectkey)实现,其中参数key为null,表示在选择具体服务实例时忽略key的条件判断。
最后,还定义了两个抽象函数。
- getServerList (ServerGroup serverGroup) : 定义了根据分组类型来获取不同的服务实例的列表。
- getLoadBalancerStats (): 定义了获取 LoadBalancerStats 对象的方法,LoadBalancerStats对象被用来存储负载均衡器中各个服务实例当前的属性和统计信息。这些信息非常有用,我们可以利用这些信息来观察负载均衡器的运行情况,同时这些信息也是用来制定负载均衡策略的重要依据。
BaseLoadBalancer
BaseLoadBalancer类是Ribbon负载均衡器的基础实现类,在该类中定义了很多关于负载均衡器相关的基础内容。
DynamicServerListLoadBalancer
DynamicServerListLoadBalancer 类继承于 BaseLoadBalancer 类,它是对基础负载均衡器的扩展。在该负载均衡器中,实现了服务实例清单在运行期的动态更新能力;同时,它还具备了对服务实例清单的过滤功能,也就是说,我们可以通过过滤器来选择性地获取一批服务实例清单。
ZoneAwareLoadBalancer
ZoneAwareLoadBalancer 负载均衡器是对 DynamicServerListLoadBalancer的扩展。在 DynamicServerListLoadBalancer中,我们可以看到它并没有重写选择具体服务实例的chooseServer函数,所以它依然会采用在BaseLoadBalancer中实现的算法。使用 RoundRobinRule规则,以线性轮询的方式来选择调用的服务实例,该算法实现简单并没有区域(Zone) 的概念,所以它会把所有实例视为一个Zone下的节点来看待,这样就会周期性地产生跨区域(Zone) 访问的情况,由于跨区域会产生更高的延迟,这些实例主要以防止区域性故障实现高可用为目的而不能作为常规访问的实例,所以在多区域部署的情况下会有一定的性能问题,而该负载均衡器则可以避免这样的问题。
负载均衡策略
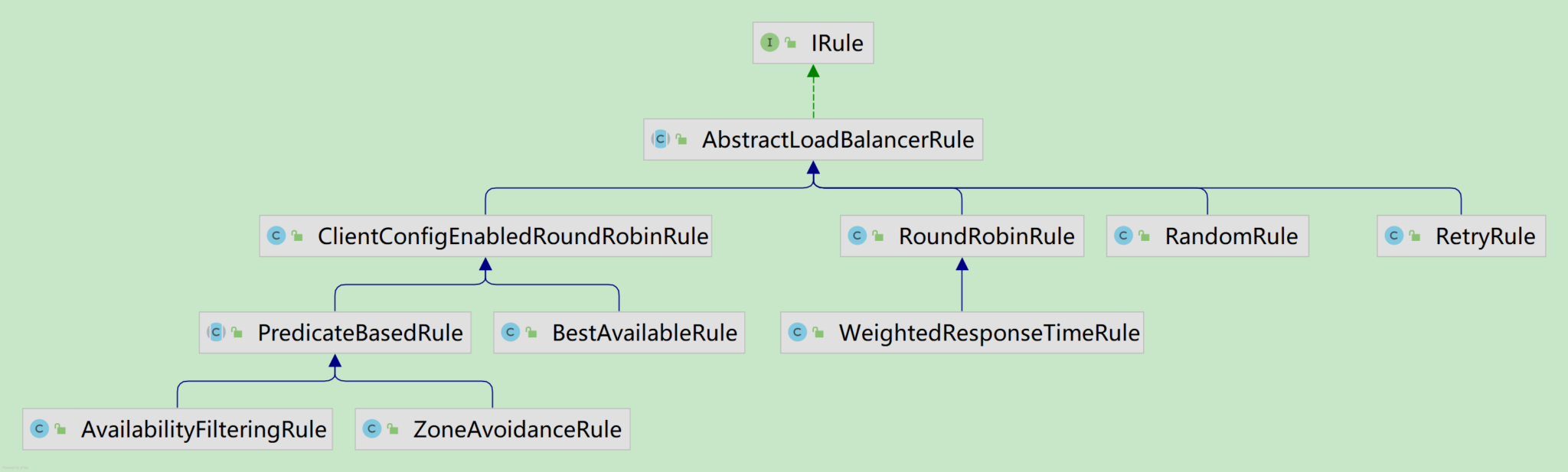
在Ribbon中实现了非常多的选择策略,如下图所示:
| 规则名称 | 特点 |
| AvailabilityFilteringRule | 过滤掉一直连接失败的被标记为circuit tripped的后端Server,并过滤掉那些高并发的后端Server或者使用一个AvailabilityPredicate来包含过滤server的逻辑,其实就是检查status里记录的各个server的运行状态 |
| BestAvailableRule | 选择一个最小的并发请求的server,逐个考察server,如果Server被tripped了,则跳过 |
| RandomRule | 随机选择一个Server |
| ResponseTimeWeightedRule | 已废弃,作用同WeightedResponseTimeRule |
| WeightedResponseTimeRule | 根据响应时间加权,响应时间越长,权重越小,被选中的可能性越低 |
| RetryRule | 对选定的负载均衡策略加上重试机制,在一个配置时间段内当选择Server不成功,则一直尝试使用subRule的方式选择一个可用的Server。 |
| RoundRobinRule | 轮询选择,轮询index,选择index对应位置的Server |
| ZoneAvoidanceRule | 默认的负载均衡策略。 复合判断Server所在区域的性能和Server的可用性选择Server,在没有区域的环境下,类似于轮询(RoundRobinRule)。 |
AbstractLoadBalancerRule
负载均衡策略的抽象类,在该抽象类中定义了负载均衡器ILoadBalancer对象,该对象能够在具体实现选择服务策略时,获取到一些负载均衡器中维护的信息来作为分配依据,并以此设计一些算法来实现针对特定场景的高效策略。
RandomRule
随机选择一个实例。
IRule接口的 choose(Object key) 函数实现 ,委托给了该类中的choose (ILoadBalancer lb, Object key),该方法增加了一个负载均衡器对象的参数。从具体的实现上看,它会使用传入的负载均衡器来获得可用实例列表upList和所有实例列表allList,并通过 rand.nextlnt(serverCount)函数来获取一个随机数,并将该随机数作为upList的索引值来返回具体实例。同时,具体的选择逻辑在一个while(server == null)循环之内,而根据选择逻辑的实现,正常情况下每次选择都应该选出一个服务实例,如果出现死循环获取不到服务实例时,则很有可能存在并发的Bug。
RoundRobinRule
线性轮询选择一个实例。
它的具体实现如下,其详细结构与RandomRule非常类似。除了循环条件不同外,就是从可用列表中获取所谓的逻辑不同。从循环条件中,我们可以看到增加了一个count计数变量,该变量会在每次循环之后累加,也就是说,如果一直选择不到server超 过 10次,那么就会结束尝试,并打印一个警告信息 No available alive servers after 10 tries from load balancer: …而线性轮询的实现则是通过Atomiclnteger nextServerCyclicCounter对象实现,每次进行实例选择时通过调用incrementAndGetModulo函数实现递增。
RetryRule
使用重试机制选择实例。
从下面的实现中我们可以看到,在其内部还定义了一个IRule对象,默认使用了 RoundRobinRule实例。而在choose方法中则实现了对内部定义的策略进行反复尝试的策略,若期间能够选择到具体的服务实例就返回,若选择不到就根据设置的尝试结束时间为阈值(maxRetryMillis参数定义的值 + choose方法开始执行的时间戳),当超过该阈值后就返回null。
WeightedResponseTimeRule
根据响应时间权重来选择实例。
该策略是对RoundRobinRule的扩展,根据实例的响应时间来计算权重,并根据权重来挑选实例,如果统计数据不足,则降级为RoundRobinRule。
它的实现主要有三个核心内容。
- 定时任务
- 初始化的时候会通过 serverWeightTimer.schedule (new DynamicServerWeightTask () , 0, serverWeightTaskTimerInterval)启动一个定时任务,用来为每个实例计算权重,该任务默认30 秒执行一次。
- 权重计算
- 存储权重的对象:List<Double> accumulatedWeights = new ArrayList<Double> () ,该 List中每个权重值所处的位置对应了所有实例在清单中的位置。
- 维护实例权重通过maintainWeights函数实现。该函数的实现主要分为两个步骤:
- 根据LoadBalancerStats中记录的每个实例的统计信息,累加所有实例的平均响应时间,得到总平均响应时间totalResponseTime。
- 为实例清单逐个计算权重,计算规则为weightSoFar+totalResponseTime—实例的平均响应时间,其中weightSoFar初始化为零,并且每计算好一个权重需要累加到weightSoFar上供下一次计算使用。
- 举个简单的例子来理解这个计算过程,假设有4个实例A、B、C、D,它们的平均响应时间为10、40、80、100,所以总响应时间是10+40+80+100=230,每个实例的权重为总响应时间与实例自身的平均响应时间的差的累积所得,所以实例A、B、C、D的权重
分别如下所示。
• 实例A:230-10=220
• 实例B:220+(230-40)=410
• 实例C:410+(230-80)=560
• 实例D:560+(230-100)=690
这里的权重值只是表示了各实例权重区间的上限,并非某个实例的优先级,所以不是数值越大被选中的概率就越大。根据上面示例的权重计算结果,可以得到每个实例的权重区间。
• 实例A:[0,220]
• 实例B:(220,410]
• 实例C:(410,560]
• 实例D:(560,690)
不难发现,实际上每个区间的宽度就是:总的平均响应时间-实例的平均响应时间,所以实例的平均响应时间越短、权重区间的宽度越大,而权重区间的宽度越大被选中的概率就越高。可能很多读者会问,这些区间边界的开闭是如何确定的呢?为什么不那么规则?下面我们会通过实例选择算法的解读来解释。
- 举个简单的例子来理解这个计算过程,假设有4个实例A、B、C、D,它们的平均响应时间为10、40、80、100,所以总响应时间是10+40+80+100=230,每个实例的权重为总响应时间与实例自身的平均响应时间的差的累积所得,所以实例A、B、C、D的权重
- 实例选择
- WeightedResponseTimeRule选择实例的核心就两步:
- 生成一个[ 0 , 最大权重值)区间内的随机数。
- 遍历权重列表,比较权重值与随机数的大小,如果权重值大于等于随机数,就拿当前权重列表的索引值去服务实例列表中获取具体的实例。权重区间边界的开闭原则,正常每个区间为(x, y]的形式,但是第一个实例和最后一个实例为什么不同呢?由于随机数的最小取值可以为0 , 所以第一个实例的下限是闭区间,同时随机数的最大值取不到最大权重值,所以最后一个实例的上限是开区间。若继续以上面的数据为例进行服务实例的选择,则该方法会从[0, 690)区间中选出一个随机数,比如选出的随机数为230,由于该值位于第二个区间,所以此时就会选择实例 B 来进行请求。
- WeightedResponseTimeRule选择实例的核心就两步:
这个算法我有疑问
假如三台实例,平均响应时间如下:
1 1000 2000
那么总时间是:1 + 1000 + 2000 = 3001
那么权重分别是:3000 2001 1001
它们被调用到的概率之比就是:3:2:1
这个看起来不合理。第一台机器那么快,竟然和第二台那么慢的机器差不多的概率。
个人的优化思路:直接用速度之比算权重,即:1/1 1/1000 1/2000
它们权重(被调用到的概率)就是:2000 2 1,这样就很合理了!
ClientConfigEnabledRoundRobinRule
该策略较为特殊,我们一般不直接使用它。因为它本身并没有实现什么特殊的处理逻辑,正如下面的源码所示,在它的内部定义了一个RoundRobinRule策略,而 choose函数的实现也正是使用了 RoundRobinRule的线性轮询机制,所以它实现的功能实际上与 RoundRobinRule相同,那么定义它有什么特殊的用处呢?
虽然我们不会直接使用该策略,但是通过继承该策略,默认的choose就实现了线性轮询机制,在子类中做一些高级策略时通常有可能会存在一些无法实施的情况,那么就可以用父类的实现作为备选。在后文中我们将继续介绍的高级策略均是基于ClientConfigEnabledRoundRobinRule 的扩展。
BestAvailableRule
该策略继承自ClientConfigEnabledRoundRobinRule,在实现中它注入了负载均衡器的统计对象LoadBalancerStats,同时在具体的choose算法中利用LoadBalancerStats保存的实例统计信息来选择满足要求的实例。它通过遍历负载均衡器中维护的所有服务实例,会过滤掉故障的实例,并找出并发请求数最小的一个,所以该策略的特性是可选出最空闲的实例。
同时,由于该算法的核心依据是统计对象loadBalancerStats,当其为空的时候,该策略是无法执行的。所以从源码中我们可以看到,当 loadBalancerStats为空的时候 ,它会采用父类的线性轮询策略,正如我们在介绍ClientConfigEnabledRoundRobinRule时那样,它的子类在无法满足实现高级策略的时候,可以使用线性轮询策略的特性。后面将要介绍的策略因为也都继承自ClientConfigEnabledRoundRobinRule,所以它们都会具有这样的特性。
PredicateBasedRule
这是一个抽象策略,它也继承了 ClientConfigEnabledRoundRobinRule,从其命名中可以猜出这是一个基于Predicate实现的策略, Predicate是 Google Guava Collection工具对集合进行过滤的条件接口。
它定义了一个抽象函数getPredicate来获取AbstractServerPredicate 对象的实现,而在 choose 函数中, 通过AbstractServerPredicate 的chooseRoundRobinAfterFiltering函数来选出具体的服务实例。从该函数的命名我们也大致能猜出它的基础逻辑:先通过子类中实现的Predicate逻辑来过滤一部分服务实例,然后再以线性轮询的方式从过滤后的实例清单中选出一个。
通过下面AbstractServerPredicate的源码片段,可以证实我们上面所做的猜测。在上面choose函数中调用的chooseRoundRobinAfterFiltering方法先通过内部定义的 getEligibleServers函数来获取备选的实例清单(实现了过滤),如果返回的清单为空,则用Optional.absent()来表不不存在,反之则以线性轮询的方式从备选清单中获取一个实例。
在了解了整体逻辑之后,我们来详细看看实现过滤功能的getEligibleServers函数。从源码上看,它的实现结构简单清晰,通过遍历服务清单,使用this,apply方法来判断实例是否需要保留,如果是就添加到结果列表中。
可能到这里,不熟悉Google Guava Collections集合工具的读者会感到困惑,这个apply在AbstractServerPredicate中找不到它的定义,那么它是如何实现过滤的呢?实际上,AbstractServerPredicate实现了com.google.common.base.Predicate接口,而apply方法是该接口中的定义,主要用来实现过滤条件的判断逻辑,它输入的参数则是过滤条件需要用到的一些信息(比如源码中的newPredicateKey(loadBalancerKey,server)),它传入了关于实例的统计信息和负载均衡器的选择算法传递过来的key)。既然在AbstractServerPredicate中我们未能找到apply的实现,所以这里的chooseRoundRobinAfterFiltering函数只是定义了一个模板策略:“先过滤清单,再轮询选择”。对于如何过滤,需要我们在AbstractServerPredicate的子类中实现apply方法来确定具体的过滤策略。后面我们将要介绍的两个策略就是基于此抽象策略实现,只是它们使用了不同的Predicate实现来完成过滤逻辑以达到不同的实例选择效果。
AvailabilityFilteringRule
该策略继承自上面介绍的抽象策略PredicateBasedRule,所以它也继承了 “先过滤清单,再轮询选择”的基本处理逻辑,其中过滤条件使用了 AvailabilityPredicate。
它的主要过滤逻辑位于shouldSkipServer方法中,它主要判断服务实例的两项内容:
- 是否故障,即断路器是否生效己断开。
- 实例的并发请求数大于阈值,默认值为2^32-1,该配置可通过参数<clientName>.<nameSpace>.ActiveConnectionsLimit 来修改。
这两项内容中只要有一个满足apply就返回 false (代表该节点可能存在故障或负载过高),都不满足就返回true。
在该策略中,除了实现了上面的过滤方法之外,对于 choose的策略也做了一些改进优化,所以父类的实现对于它来说只是一个备用选项。
它并没有像在父类中那样,先遍历所有的节点进行过滤,然后在过滤后的集合中选择实例。而是先以线性的方式选择一个实例,接着用过滤条件来判断该实例是否满足要求,若满足就直接使用该实例,若不满足要求就再选择下一个实例,并检查是否满足要求,如此循环进行,当这个过程重复了 10次还是没有找到符合要求的实例,就采用父类的实现方案。
简单地说,该策略通过线性抽样的方式直接尝试寻找可用且较空闲的实例来使用,优化了父类每次都要遍历所有实例的开销。
ZoneAvoidanceRule
该策略我们在介绍负载均衡器ZoneAwareLoadBalancer时己经提到过,它也是PredicateBasedRule的具体实现类。在之前的介绍中主要针对ZoneAvoidanceRule中用于选择Zone区域策略的一些静态函数,比如createSnapshot、getAvailableZones。
在这里我们将详细看看ZoneAvoidanceRule作为服务实例过滤条件的实现原理。从下面 ZoneAvoidanceRule的源码片段中可以看到,它使用了 CompositePredicate来进行服务实例清单的过滤。这是一个组合过滤条件,在其构造函数中,它以ZoneAvoidancePredicate 为主过滤条件,AvailabilityPredicate 为次过滤条件初始化了组合过滤条件的实例。
ZoneAvoidanceRule在实现的时吴并没有像AvailabilityFilteringRule那样重写choose函数来优化,所以它完全遵循了父类的过滤主逻辑:“先过滤清单,再轮询选择”。其中过滤清单的条件就是我们上面提到的以ZoneAvoidancePredicate为主过滤条件、AvailabilityPredicate为次过滤条件的组合过滤条件Compositepredicate。从CompositePredicate的源码片段中,我们可以看到它定义了一个主过滤条件AbstractServerPredicatedelegate以及一组次过滤条件列表List fallbacks, 所以它的次过滤列表是可以拥有多个的,并且由于它采用了 List存储所以次过滤条件是按顺序执行的。
在获取过滤结果的实现函数getEligibleServers中,它的处理逻辑如下所示:
- 使用主过滤条件对所有实例过滤并返回过滤后的实例清单。
- 依次使用次过滤条件列表中的过滤条件对主过滤条件的结果进行过滤。
- 每次过滤之后(包括主过滤条件和次过滤条件),都需要判断下面两个条件,只要有一个符合就不再进行过滤,将当前结果返回供线性轮询算法选择:
- 过滤后的实例总数 > = 最小过滤实例数(minimalFilteredServers,默认为 1)。
- 过滤后的实例比例 > 最小过滤百分比(minimalFilteredPercentage,默认为0)。

请先 !